 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs 'Unsupervised Learning' a Misconceived Term?
Paper and Code
Apr 05, 2019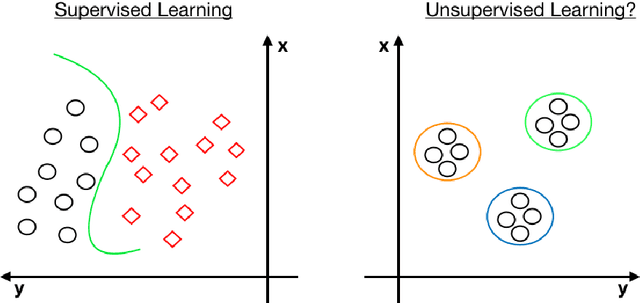
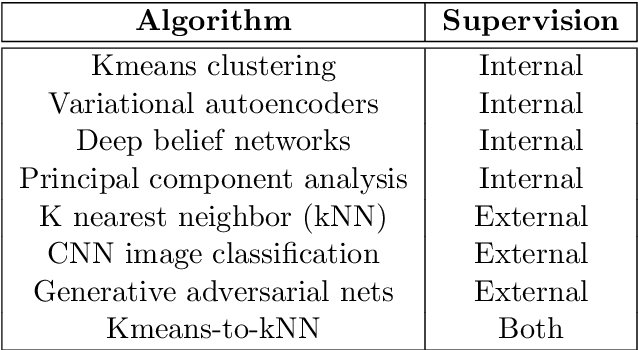
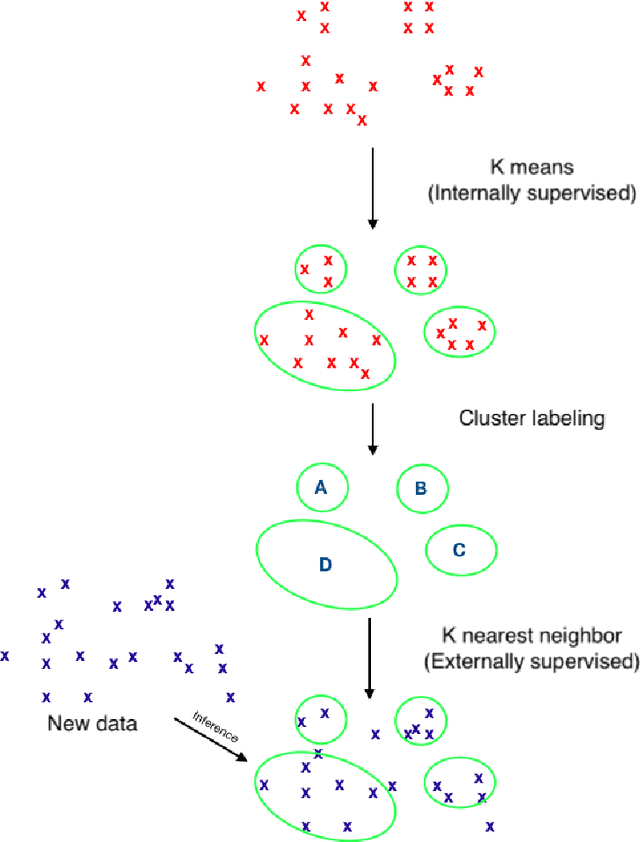

Is all of machine learning supervised to some degree? The field of machine learning has traditionally been categorized pedagogically into $supervised~vs~unsupervised~learning$; where supervised learning has typically referred to learning from labeled data, while unsupervised learning has typically referred to learning from unlabeled data. In this paper, we assert that all machine learning is in fact supervised to some degree, and that the scope of supervision is necessarily commensurate to the scope of learning potential. In particular, we argue that clustering algorithms such as k-means, and dimensionality reduction algorithms such as principal component analysis, variational autoencoders, and deep belief networks are each internally supervised by the data itself to learn their respective representations of its features. Furthermore, these algorithms are not capable of external inference until their respective outputs (clusters, principal components, or representation codes) have been identified and externally labeled in effect. As such, they do not suffice as examples of unsupervised learning. We propose that the categorization `supervised vs unsupervised learning' be dispensed with, and instead, learning algorithms be categorized as either $internally~or~externally~supervised$ (or both). We believe this change in perspective will yield new fundamental insights into the structure and character of data and of learning algorithms.