 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Rewiring Actually Helpful in Graph Neural Networks?
Paper and Code
May 31, 2023
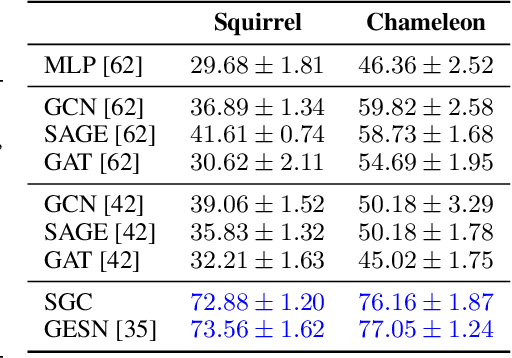
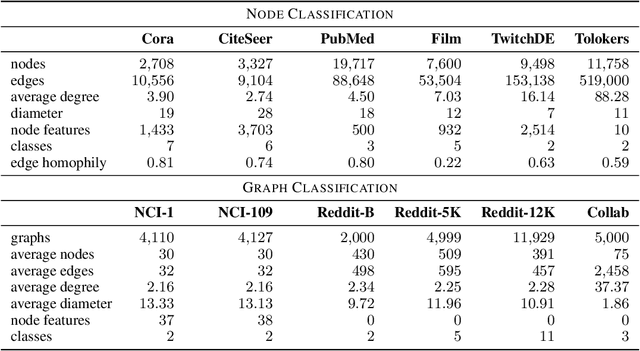
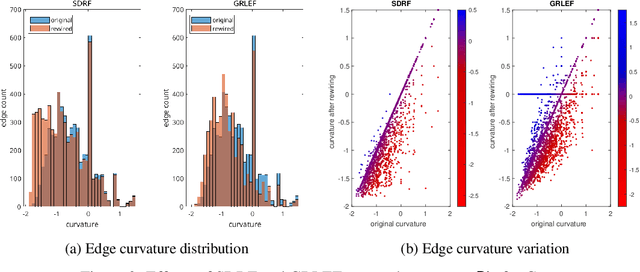
Graph neural networks compute node representations by performing multiple message-passing steps that consist in local aggregations of node features. Having deep models that can leverage longer-range interactions between nodes is hindered by the issues of over-smoothing and over-squashing. In particular, the latter is attributed to the graph topology which guides the message-passing, causing a node representation to become insensitive to information contained at distant nodes. Many graph rewiring methods have been proposed to remedy or mitigate this problem. However, properly evaluating the benefits of these methods is made difficult by the coupling of over-squashing with other issues strictly related to model training, such as vanishing gradients. Therefore, we propose an evaluation setting based on message-passing models that do not require training to compute node and graph representations. We perform a systematic experimental comparison on real-world node and graph classification tasks, showing that rewiring the underlying graph rarely does confer a practical benefit for message-passing.