 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Cross-Attention Preferable to Self-Attention for Multi-Modal Emotion Recognition?
Paper and Code
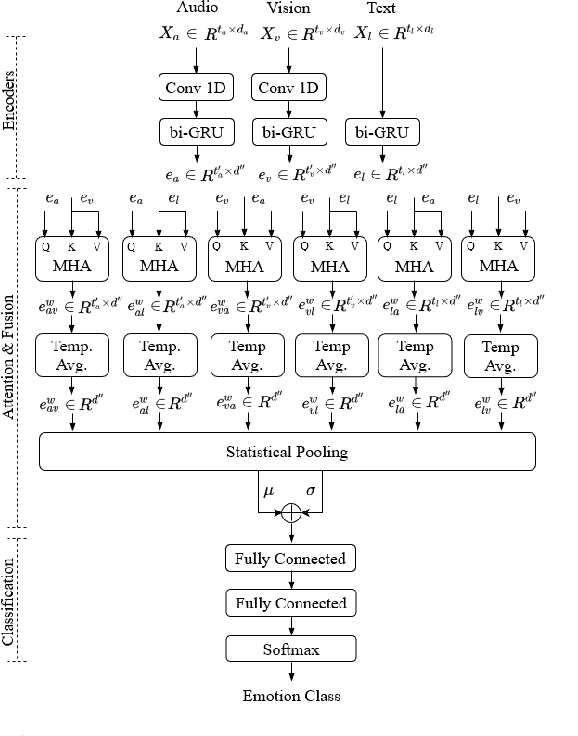
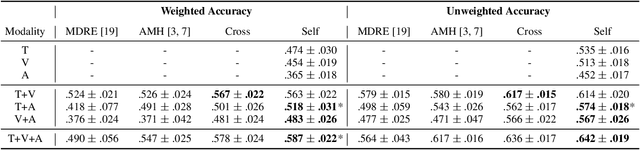
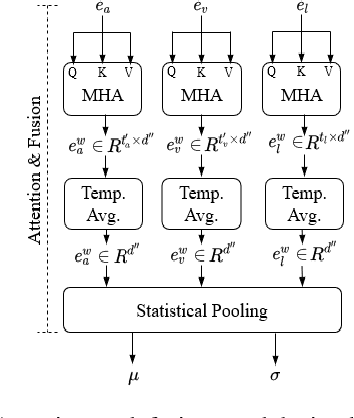

Humans express their emotions via facial expressions, voice intonation and word choices. To infer the nature of the underlying emotion, recognition models may use a single modality, such as vision, audio, and text, or a combination of modalities. Generally, models that fuse complementary information from multiple modalities outperform their uni-modal counterparts. However, a successful model that fuses modalities requires components that can effectively aggregate task-relevant information from each modality. As cross-modal attention is seen as an effective mechanism for multi-modal fusion, in this paper we quantify the gain that such a mechanism brings compared to the corresponding self-attention mechanism. To this end, we implement and compare a cross-attention and a self-attention model. In addition to attention, each model uses convolutional layers for local feature extraction and recurrent layers for global sequential modelling. We compare the models using different modality combinations for a 7-class emotion classification task using the IEMOCAP dataset. Experimental results indicate that albeit both models improve upon the state-of-the-art in terms of weighted and unweighted accuracy for tri- and bi-modal configurations, their performance is generally statistically comparable. The code to replicate the experiments is available at https://github.com/smartcameras/SelfCrossAttn