 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigations on Audiovisual Emotion Recognition in Noisy Conditions
Paper and Code
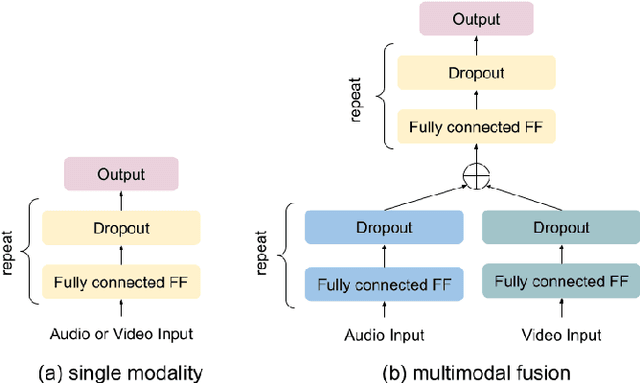

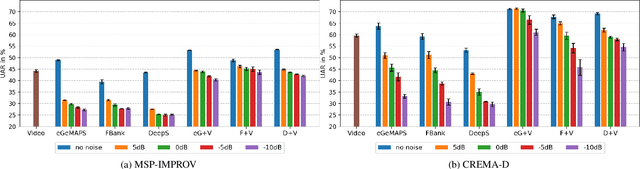
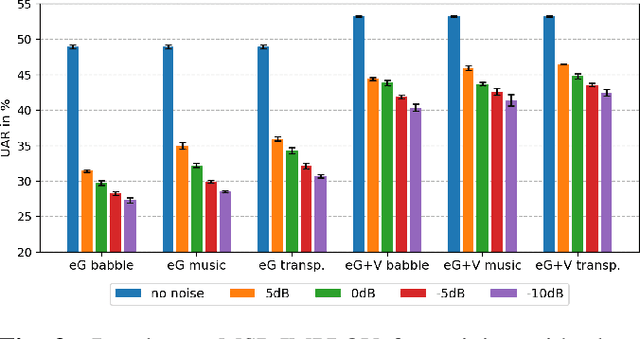
In this paper we explore audiovisual emotion recognition under noisy acoustic conditions with a focus on speech features. We attempt to answer the following research questions: (i) How does speech emotion recognition perform on noisy data? and (ii) To what extend does a multimodal approach improve the accuracy and compensate for potential performance degradation at different noise levels? We present an analytical investigation on two emotion datasets with superimposed noise at different signal-to-noise ratios, comparing three types of acoustic features. Visual features are incorporated with a hybrid fusion approach: The first neural network layers are separate modality-specific ones, followed by at least one shared layer before the final prediction. The results show a significant performance decrease when a model trained on clean audio is applied to noisy data and that the addition of visual features alleviates this effect.