 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Multimodal and Agential Interactions in Human-Robot Imitation, based on frameworks of Predictive Coding and Active Inference
Paper and Code
Feb 05, 2020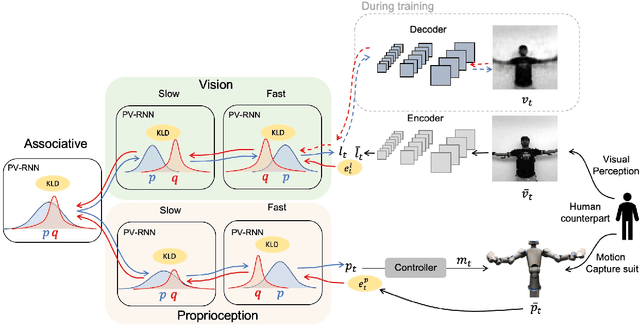

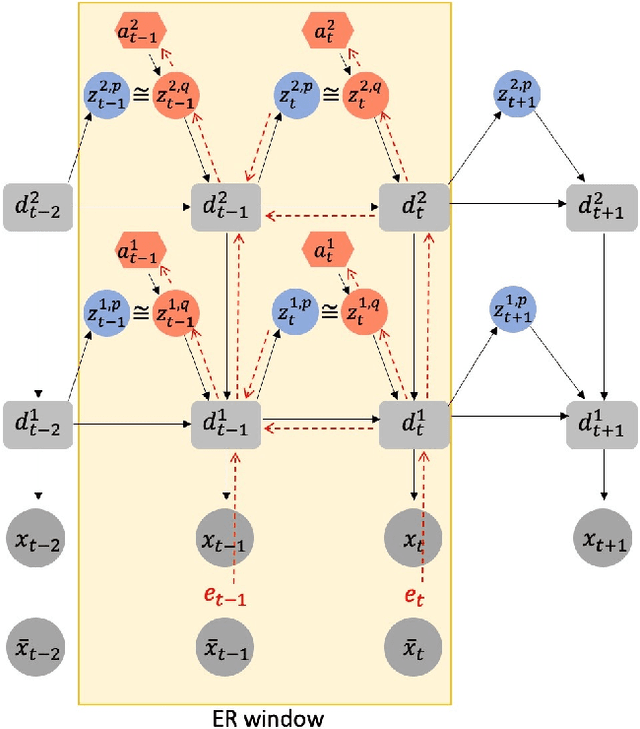

This study proposes a model for multimodal, imitative interaction of agents, based on frameworks of predictive coding and active inference, using a variational Bayes recurrent neural network. The model dynamically predicts visual sensation and proprioception simultaneously through generative processes by associating both modalities. It also updates the internal state and generates actions by maximizing the lower bound. A key feature of the model is that the complexity of each modality, as well as of the entire network can be regulated independently. We hypothesize that regulation of complexity offers a common perspective over two distinct properties of embodied agents: coordination of multimodalities and strength of agent intention or belief in social interactions. We evaluate the hypotheses by conducting experiments on imitative human-robot interactions in two different scenarios using the model. First, regulation of complexity was changed between the vision module and the proprioception module during learning. The results showed that complexity of the vision module should be more strongly regulated than that of proprioception because of its greater randomness. Second, the strength of complexity regulation of the whole network in the robot was varied during test imitation after learning. We found that this affects human-robot interactions significantly. With weaker regulation of complexity, the robot tends to move more egocentrically, without adapting to the human counterpart. On the other hand, with stronger regulation, the robot tends to follow its human counterpart by adapting its internal state. Our study concludes that the strength with which complexity is regulated significantly affects the nature of dynamic interactions between different modalities and between individual agents in a social setting.