 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Robustness of Counterfactual Learning to Rank Models: A Reproducibility Study
Paper and Code

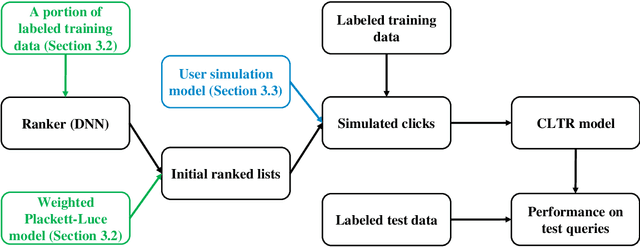
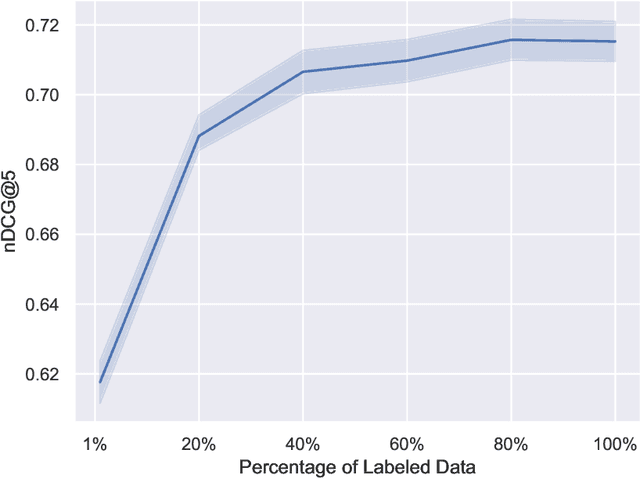
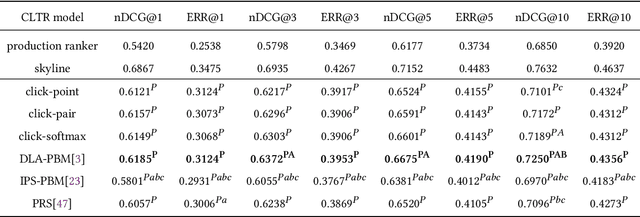
Counterfactual learning to rank (CLTR) has attracted extensive attention in the IR community for its ability to leverage massive logged user interaction data to train ranking models. While the CLTR models can be theoretically unbiased when the user behavior assumption is correct and the propensity estimation is accurate, their effectiveness is usually empirically evaluated via simulation-based experiments due to a lack of widely-available, large-scale, real click logs. However, the mainstream simulation-based experiments are somewhat limited as they often feature a single, deterministic production ranker and simplified user simulation models to generate the synthetic click logs. As a result, the robustness of CLTR models in complex and diverse situations is largely unknown and needs further investigation. To address this problem, in this paper, we aim to investigate the robustness of existing CLTR models in a reproducibility study with extensive simulation-based experiments that (1) use both deterministic and stochastic production rankers, each with different ranking performance, and (2) leverage multiple user simulation models with different user behavior assumptions. We find that the DLA models and IPS-DCM show better robustness under various simulation settings than IPS-PBM and PRS with offline propensity estimation. Besides, the existing CLTR models often fail to outperform the naive click baselines when the production ranker has relatively high ranking performance or certain randomness, which suggests an urgent need for developing new CLTR algorithms that work for these settings.