 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Bias In Automatic Toxic Comment Detection: An Empirical Study
Paper and Code
Aug 14, 2021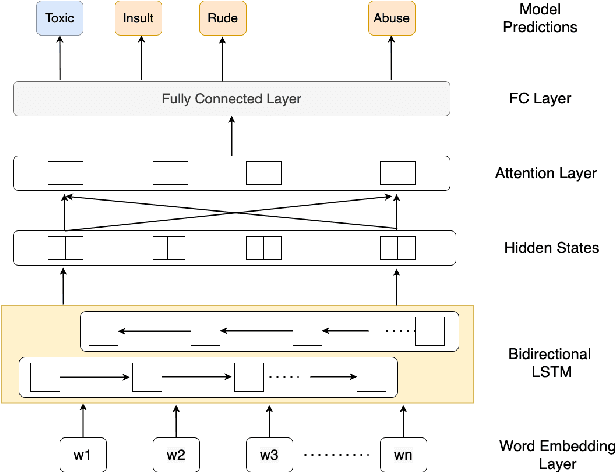
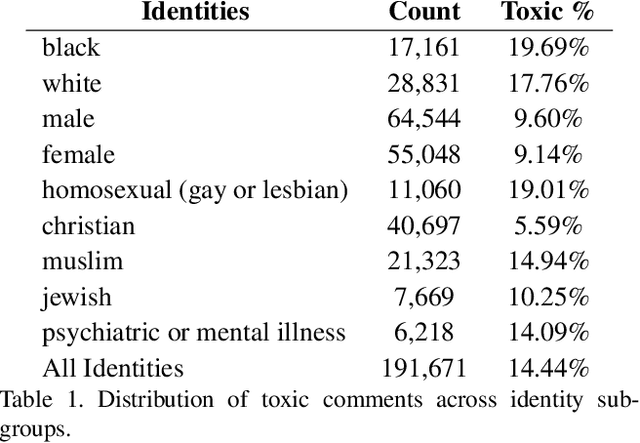
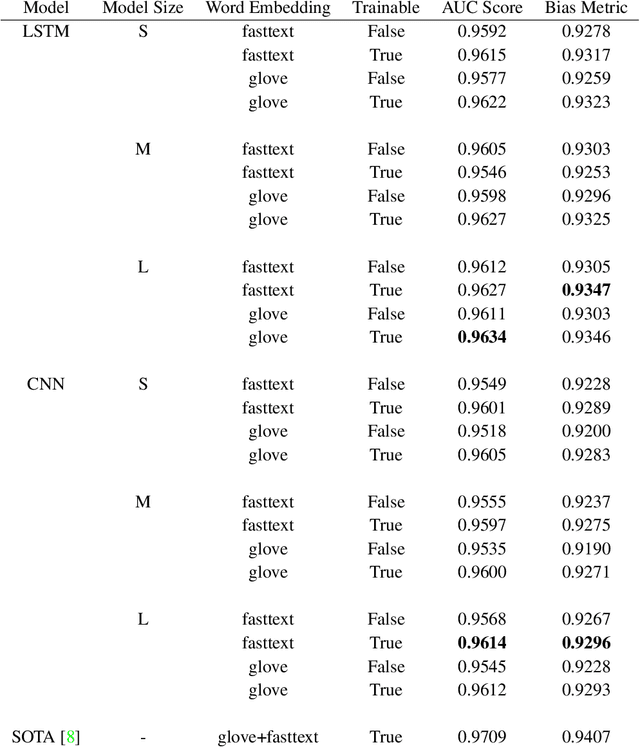
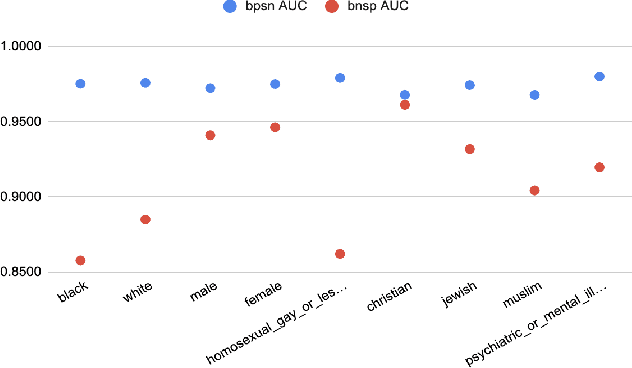
With surge in online platforms, there has been an upsurge in the user engagement on these platforms via comments and reactions. A large portion of such textual comments are abusive, rude and offensive to the audience. With machine learning systems in-place to check such comments coming onto platform, biases present in the training data gets passed onto the classifier leading to discrimination against a set of classes, religion and gender. In this work, we evaluate different classifiers and feature to estimate the bias in these classifiers along with their performance on downstream task of toxicity classification. Results show that improvement in performance of automatic toxic comment detection models is positively correlated to mitigating biases in these models. In our work, LSTM with attention mechanism proved to be a better modelling strategy than a CNN model. Further analysis shows that fasttext embeddings is marginally preferable than glove embeddings on training models for toxicity comment detection. Deeper analysis reveals the findings that such automatic models are particularly biased to specific identity groups even though the model has a high AUC score. Finally, in effort to mitigate bias in toxicity detection models, a multi-task setup trained with auxiliary task of toxicity sub-types proved to be useful leading to upto 0.26% (6% relative) gain in AUC scores.