 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverted-File k-Means Clustering: Performance Analysis
Paper and Code
Feb 21, 2020
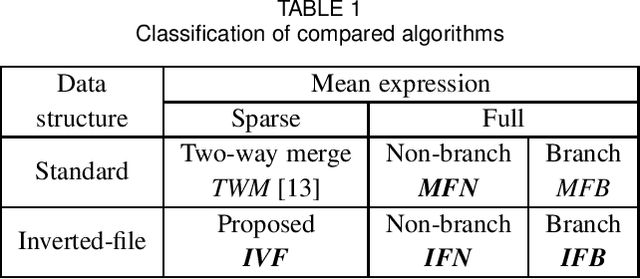

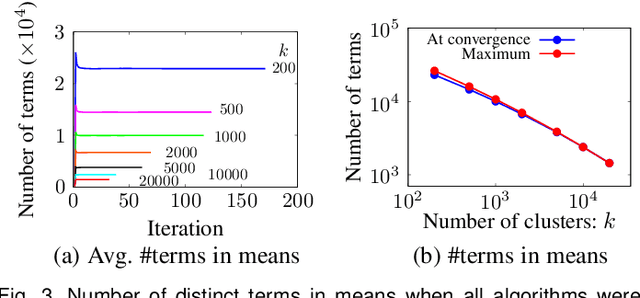
This paper presents an inverted-file k-means clustering algorithm (IVF) suitable for a large-scale sparse data set with potentially numerous classes. Given such a data set, IVF efficiently works at high-speed and with low memory consumption, which keeps the same solution as a standard Lloyd's algorithm. The high performance arises from two distinct data representations. One is a sparse expression for both the object and mean feature vectors. The other is an inverted-file data structure for a set of the mean feature vectors. To confirm the effect of these representations, we design three algorithms using distinct data structures and expressions for comparison. We experimentally demonstrate that IVF achieves better performance than the designed algorithms when they are applied to large-scale real document data sets in a modern computer system equipped with superscalar out-of-order processors and a deep hierarchical memory system. We also introduce a simple yet practical clock-cycle per instruction (CPI) model for speed-performance analysis. Analytical results reveal that IVF suppresses three performance degradation factors: the numbers of cache misses, branch mispredictions, and the completed instructions.