Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroduction to the CoNLL-2000 Shared Task: Chunking
Paper and Code
Sep 18, 2000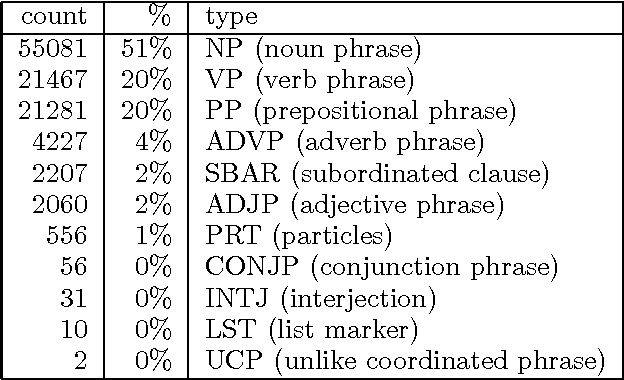
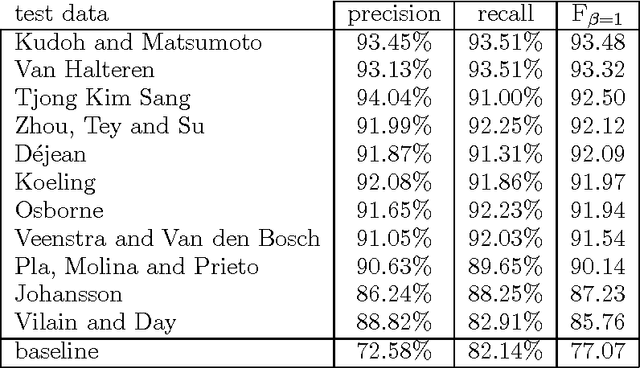
We describe the CoNLL-2000 shared task: dividing text into syntactically related non-overlapping groups of words, so-called text chunking. We give background information on the data sets, present a general overview of the systems that have taken part in the shared task and briefly discuss their performance.
* Proceedings of CoNLL-2000 and LLL-2000, Lisbon, Portugal * 6 pages
View paper on