 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Quality Assessment of Arguments
Paper and Code
Oct 23, 2020

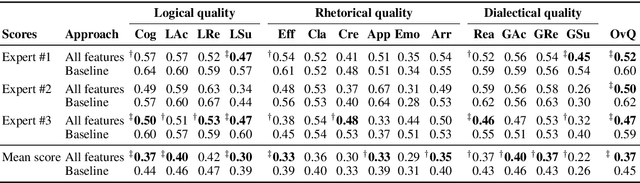

Several quality dimensions of natural language arguments have been investigated. Some are likely to be reflected in linguistic features (e.g., an argument's arrangement), whereas others depend on context (e.g., relevance) or topic knowledge (e.g., acceptability). In this paper, we study the intrinsic computational assessment of 15 dimensions, i.e., only learning from an argument's text. In systematic experiments with eight feature types on an existing corpus, we observe moderate but significant learning success for most dimensions. Rhetorical quality seems hardest to assess, and subjectivity features turn out strong, although length bias in the corpus impedes full validity. We also find that human assessors differ more clearly to each other than to our approach.