 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Transformer's Attention Dynamic Memory and Visualizing the Semantic Information Flow of GPT
Paper and Code

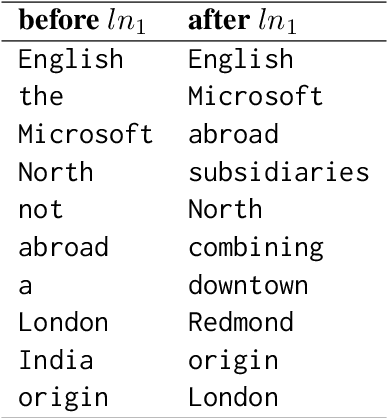


Recent advances in interpretability suggest we can project weights and hidden states of transformer-based language models (LMs) to their vocabulary, a transformation that makes them human interpretable and enables us to assign semantics to what was seen only as numerical vectors. In this paper, we interpret LM attention heads and memory values, the vectors the models dynamically create and recall while processing a given input. By analyzing the tokens they represent through this projection, we identify patterns in the information flow inside the attention mechanism. Based on these discoveries, we create a tool to visualize a forward pass of Generative Pre-trained Transformers (GPTs) as an interactive flow graph, with nodes representing neurons or hidden states and edges representing the interactions between them. Our visualization simplifies huge amounts of data into easy-to-read plots that reflect why models output their results. We demonstrate the utility of our modeling by identifying the effect LM components have on the intermediate processing in the model before outputting a prediction. For instance, we discover that layer norms are used as semantic filters and find neurons that act as regularization vectors.