 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Training Aspects of Deep-Learned Error-Correcting Codes
Paper and Code
May 07, 2023


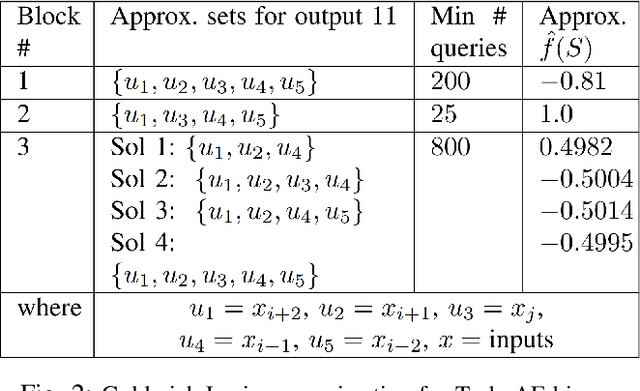
As new deep-learned error-correcting codes continue to be introduced, it is important to develop tools to interpret the designed codes and understand the training process. Prior work focusing on the deep-learned TurboAE has both interpreted the learned encoders post-hoc by mapping these onto nearby ``interpretable'' encoders, and experimentally evaluated the performance of these interpretable encoders with various decoders. Here we look at developing tools for interpreting the training process for deep-learned error-correcting codes, focusing on: 1) using the Goldreich-Levin algorithm to quickly interpret the learned encoder; 2) using Fourier coefficients as a tool for understanding the training dynamics and the loss landscape; 3) reformulating the training loss, the binary cross entropy, by relating it to encoder and decoder parameters, and the bit error rate (BER); 4) using these insights to formulate and study a new training procedure. All tools are demonstrated on TurboAE, but are applicable to other deep-learned forward error correcting codes (without feedback).