 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting and Explaining Deep Neural Networks for Classification of Audio Signals
Paper and Code


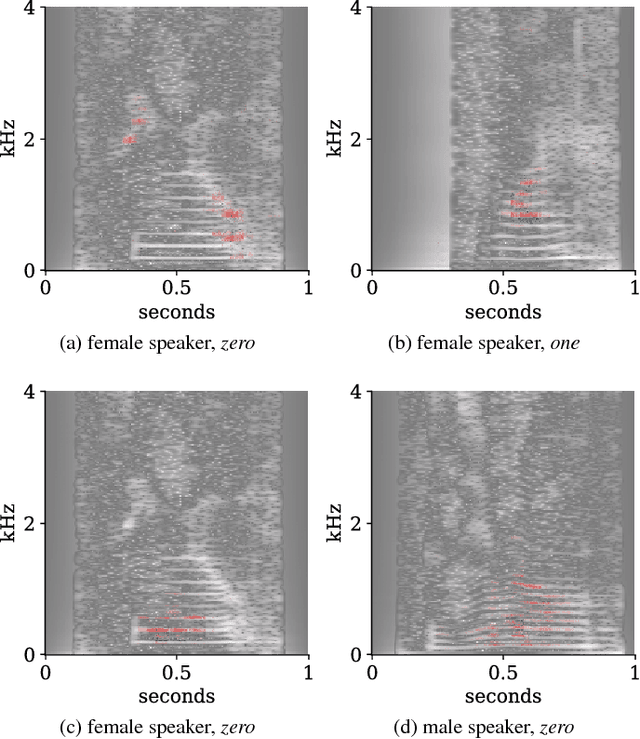
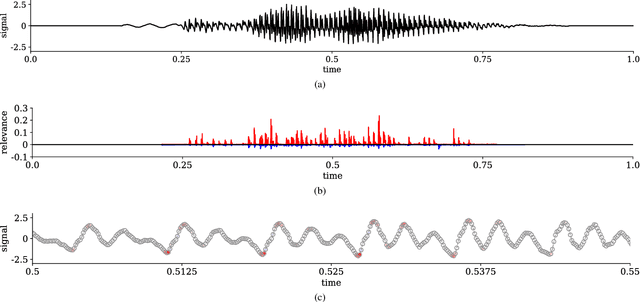
Interpretability of deep neural networks is a recently emerging area of machine learning research targeting a better understanding of how models perform feature selection and derive their classification decisions. In this paper, two neural network architectures are trained on spectrogram and raw waveform data for audio classification tasks on a newly created audio dataset and layer-wise relevance propagation (LRP), a previously proposed interpretability method, is applied to investigate the models' feature selection and decision making. It is demonstrated that the networks are highly reliant on feature marked as relevant by LRP through systematic manipulation of the input data. Our results show that by making deep audio classifiers interpretable, one can analyze and compare the properties and strategies of different models beyond classification accuracy, which potentially opens up new ways for model improvements.