 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Preference-based Reinforcement Learning with Tree-Structured Reward Functions
Paper and Code
Dec 20, 2021
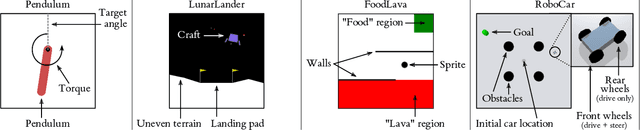


The potential of reinforcement learning (RL) to deliver aligned and performant agents is partially bottlenecked by the reward engineering problem. One alternative to heuristic trial-and-error is preference-based RL (PbRL), where a reward function is inferred from sparse human feedback. However, prior PbRL methods lack interpretability of the learned reward structure, which hampers the ability to assess robustness and alignment. We propose an online, active preference learning algorithm that constructs reward functions with the intrinsically interpretable, compositional structure of a tree. Using both synthetic and human-provided feedback, we demonstrate sample-efficient learning of tree-structured reward functions in several environments, then harness the enhanced interpretability to explore and debug for alignment.