 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Neural Computation for Real-World Compositional Visual Question Answering
Paper and Code
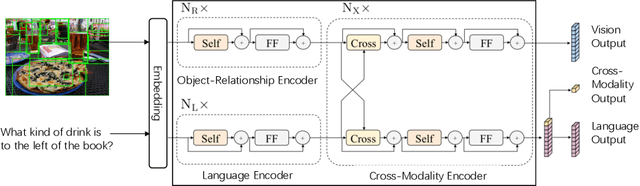
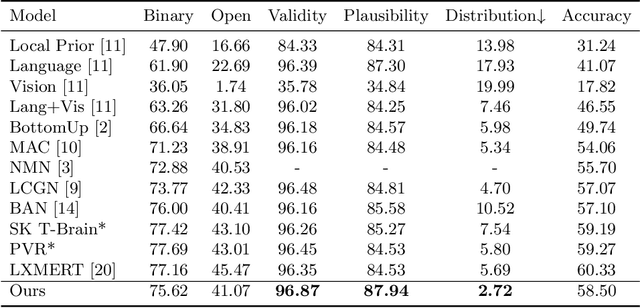


There are two main lines of research on visual question answering (VQA): compositional model with explicit multi-hop reasoning, and monolithic network with implicit reasoning in the latent feature space. The former excels in interpretability and compositionality but fails on real-world images, while the latter usually achieves better performance due to model flexibility and parameter efficiency. We aim to combine the two to build an interpretable framework for real-world compositional VQA. In our framework, images and questions are disentangled into scene graphs and programs, and a symbolic program executor runs on them with full transparency to select the attention regions, which are then iteratively passed to a visual-linguistic pre-trained encoder to predict answers. Experiments conducted on the GQA benchmark demonstrate that our framework outperforms the compositional prior arts and achieves competitive accuracy among monolithic ones. With respect to the validity, plausibility and distribution metrics, our framework surpasses others by a considerable margin.