 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability from a new lens: Integrating Stratification and Domain knowledge for Biomedical Applications
Paper and Code
Mar 15, 2023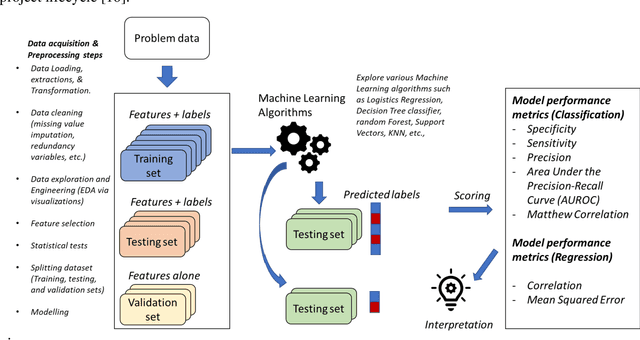
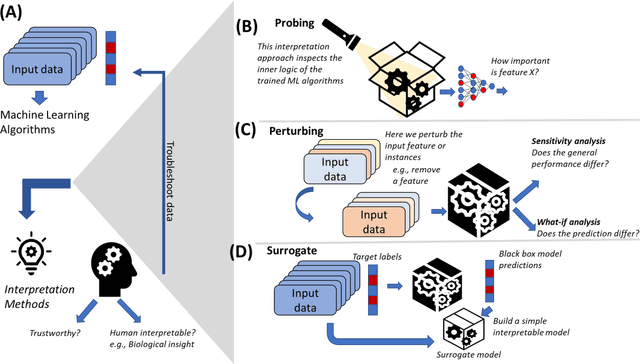
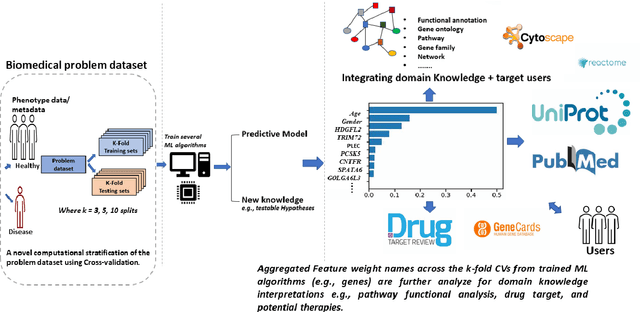
The use of machine learning (ML) techniques in the biomedical field has become increasingly important, particularly with the large amounts of data generated by the aftermath of the COVID-19 pandemic. However, due to the complex nature of biomedical datasets and the use of black-box ML models, a lack of trust and adoption by domain experts can arise. In response, interpretable ML (IML) approaches have been developed, but the curse of dimensionality in biomedical datasets can lead to model instability. This paper proposes a novel computational strategy for the stratification of biomedical problem datasets into k-fold cross-validation (CVs) and integrating domain knowledge interpretation techniques embedded into the current state-of-the-art IML frameworks. This approach can improve model stability, establish trust, and provide explanations for outcomes generated by trained IML models. Specifically, the model outcome, such as aggregated feature weight importance, can be linked to further domain knowledge interpretations using techniques like pathway functional enrichment, drug targeting, and repurposing databases. Additionally, involving end-users and clinicians in focus group discussions before and after the choice of IML framework can help guide testable hypotheses, improve performance metrics, and build trustworthy and usable IML solutions in the biomedical field. Overall, this study highlights the potential of combining advanced computational techniques with domain knowledge interpretation to enhance the effectiveness of IML solutions in the context of complex biomedical datasets.