 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterMulti:Multi-view Multimodal Interactions with Text-dominated Hierarchical High-order Fusion for Emotion Analysis
Paper and Code
Dec 20, 2022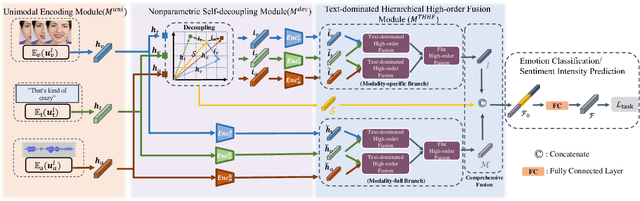
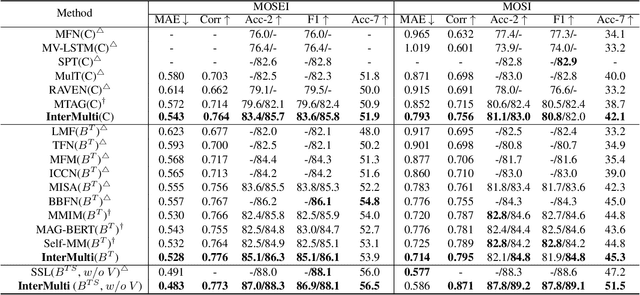
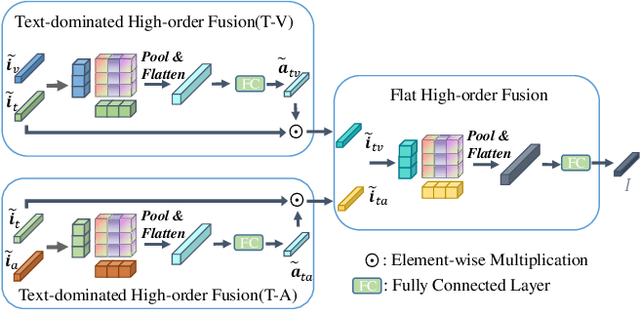
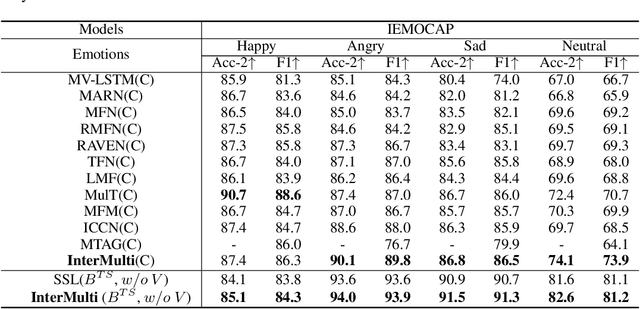
Humans are sophisticated at reading interlocutors' emotions from multimodal signals, such as speech contents, voice tones and facial expressions. However, machines might struggle to understand various emotions due to the difficulty of effectively decoding emotions from the complex interactions between multimodal signals. In this paper, we propose a multimodal emotion analysis framework, InterMulti, to capture complex multimodal interactions from different views and identify emotions from multimodal signals. Our proposed framework decomposes signals of different modalities into three kinds of multimodal interaction representations, including a modality-full interaction representation, a modality-shared interaction representation, and three modality-specific interaction representations. Additionally, to balance the contribution of different modalities and learn a more informative latent interaction representation, we developed a novel Text-dominated Hierarchical High-order Fusion(THHF) module. THHF module reasonably integrates the above three kinds of representations into a comprehensive multimodal interaction representation. Extensive experimental results on widely used datasets, (i.e.) MOSEI, MOSI and IEMOCAP, demonstrate that our method outperforms the state-of-the-art.