 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction Data Generation and Unsupervised Adaptation for Speech Language Models
Paper and Code
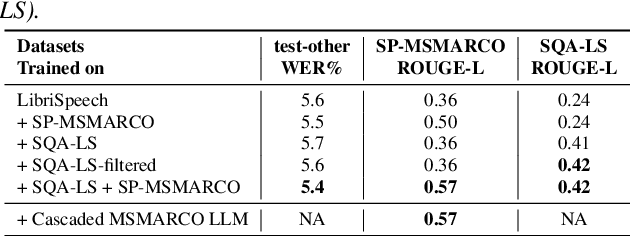
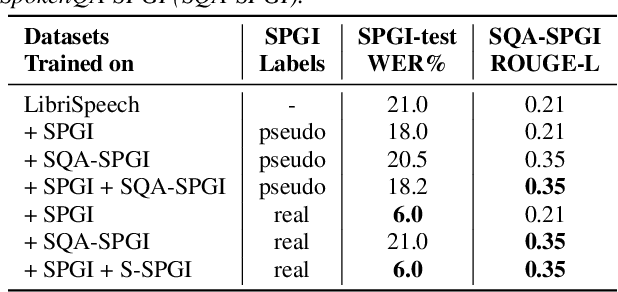

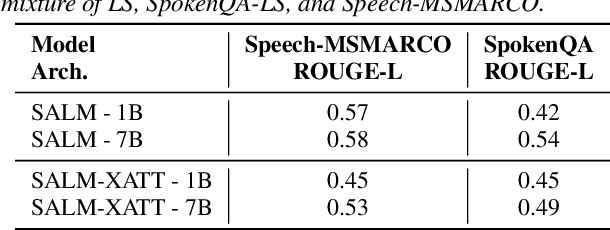
In this paper, we propose three methods for generating synthetic samples to train and evaluate multimodal large language models capable of processing both text and speech inputs. Addressing the scarcity of samples containing both modalities, synthetic data generation emerges as a crucial strategy to enhance the performance of such systems and facilitate the modeling of cross-modal relationships between the speech and text domains. Our process employs large language models to generate textual components and text-to-speech systems to generate speech components. The proposed methods offer a practical and effective means to expand the training dataset for these models. Experimental results show progress in achieving an integrated understanding of text and speech. We also highlight the potential of using unlabeled speech data to generate synthetic samples comparable in quality to those with available transcriptions, enabling the expansion of these models to more languages.