 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstaIndoor and Multi-modal Deep Learning for Indoor Scene Recognition
Paper and Code

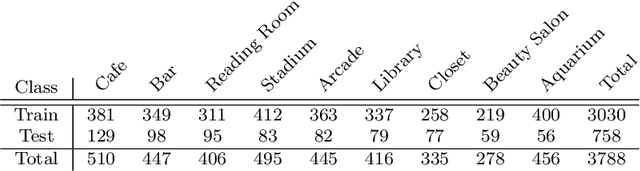
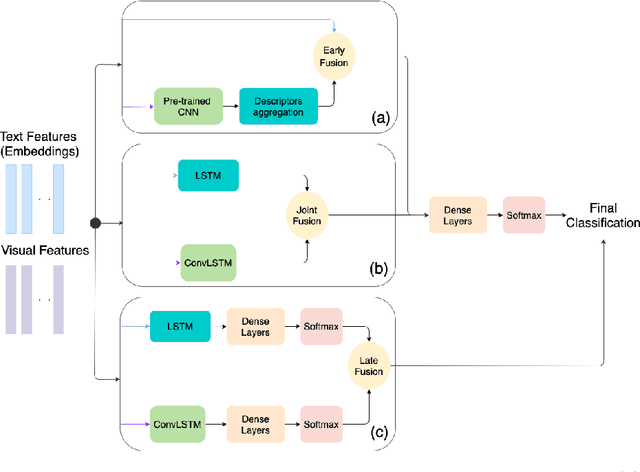
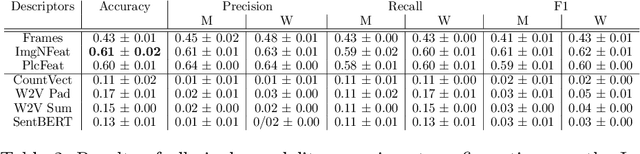
Indoor scene recognition is a growing field with great potential for behaviour understanding, robot localization, and elderly monitoring, among others. In this study, we approach the task of scene recognition from a novel standpoint, using multi-modal learning and video data gathered from social media. The accessibility and variety of social media videos can provide realistic data for modern scene recognition techniques and applications. We propose a model based on fusion of transcribed speech to text and visual features, which is used for classification on a novel dataset of social media videos of indoor scenes named InstaIndoor. Our model achieves up to 70% accuracy and 0.7 F1-Score. Furthermore, we highlight the potential of our approach by benchmarking on a YouTube-8M subset of indoor scenes as well, where it achieves 74% accuracy and 0.74 F1-Score. We hope the contributions of this work pave the way to novel research in the challenging field of indoor scene recognition.