 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInherent Inconsistencies of Feature Importance
Paper and Code
Jun 16, 2022
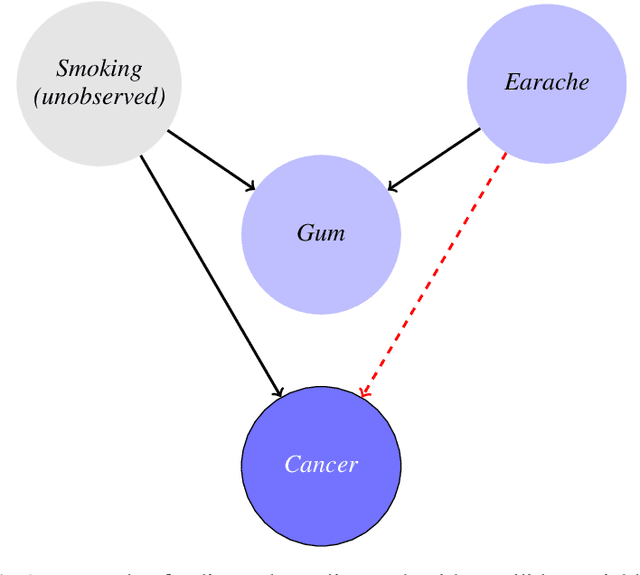
The black-box nature of modern machine learning techniques invokes a practical and ethical need for explainability. Feature importance aims to meet this need by assigning scores to features, so humans can understand their influence on predictions. Feature importance can be used to explain predictions under different settings: of the entire sample space or a specific instance; of model behavior, or the dependencies in the data themselves. However, in most cases thus far, each of these settings was studied in isolation. We attempt to develop a sound feature importance score framework by defining a small set of desired properties. Surprisingly, we prove an inconsistency theorem, showing that the expected properties cannot hold simultaneously. To overcome this difficulty, we propose the novel notion of re-partitioning the feature space into separable sets. Such sets are constructed to contain features that exhibit inter-set independence with respect to the target variable. We show that there exists a unique maximal partitioning into separable sets. Moreover, assigning scores to separable sets, instead of single features, unifies the results of commonly used feature importance scores and annihilates the inconsistencies we demonstrated.