Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInforming Autonomous Deception Systems with Cyber Expert Performance Data
Paper and Code
Aug 31, 2021
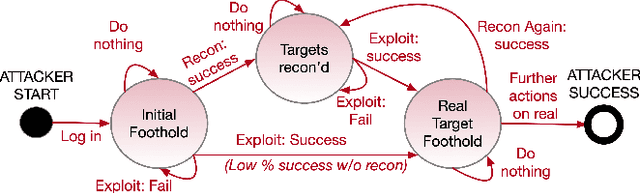
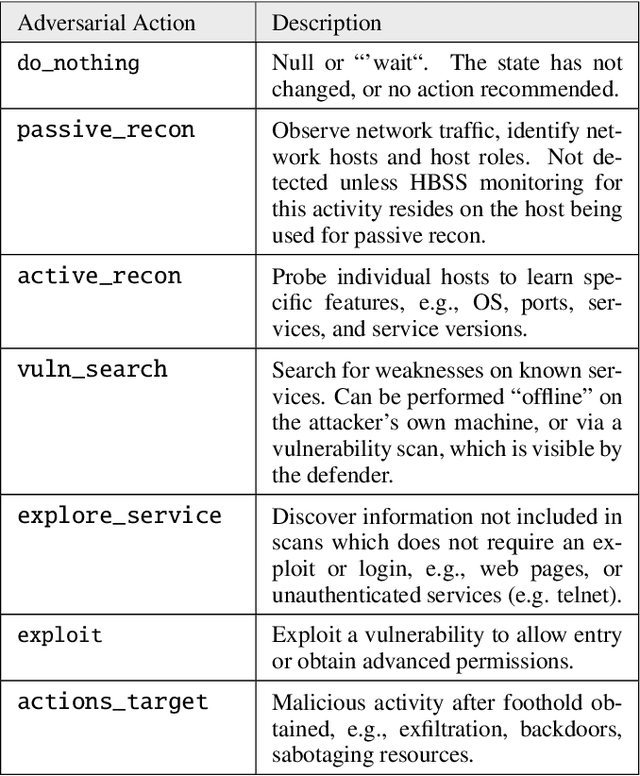
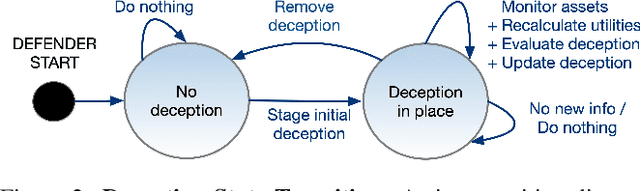
The performance of artificial intelligence (AI) algorithms in practice depends on the realism and correctness of the data, models, and feedback (labels or rewards) provided to the algorithm. This paper discusses methods for improving the realism and ecological validity of AI used for autonomous cyber defense by exploring the potential to use Inverse Reinforcement Learning (IRL) to gain insight into attacker actions, utilities of those actions, and ultimately decision points which cyber deception could thwart. The Tularosa study, as one example, provides experimental data of real-world techniques and tools commonly used by attackers, from which core data vectors can be leveraged to inform an autonomous cyber defense system.
* Presented at 1st International Workshop on Adaptive Cyber Defense,
2021 (arXiv:2108.08476)
View paper on