 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformed Group-Sparse Representation for Singing Voice Separation
Paper and Code
Jan 09, 2018

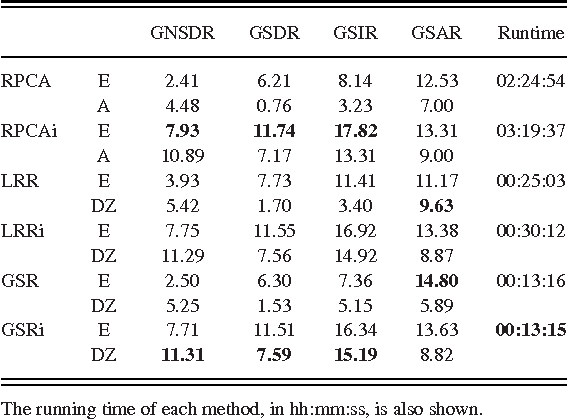

Singing voice separation attempts to separate the vocal and instrumental parts of a music recording, which is a fundamental problem in music information retrieval. Recent work on singing voice separation has shown that the low-rank representation and informed separation approaches are both able to improve separation quality. However, low-rank optimizations are computationally inefficient due to the use of singular value decompositions. Therefore, in this paper, we propose a new linear-time algorithm called informed group-sparse representation, and use it to separate the vocals from music using pitch annotations as side information. Experimental results on the iKala dataset confirm the efficacy of our approach, suggesting that the music accompaniment follows a group-sparse structure given a pre-trained instrumental dictionary. We also show how our work can be easily extended to accommodate multiple dictionaries using the DSD100 dataset.