 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Measures of Dataset Difficulty
Paper and Code

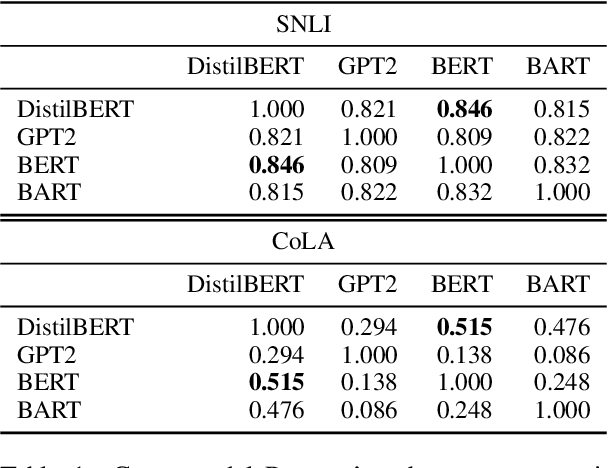
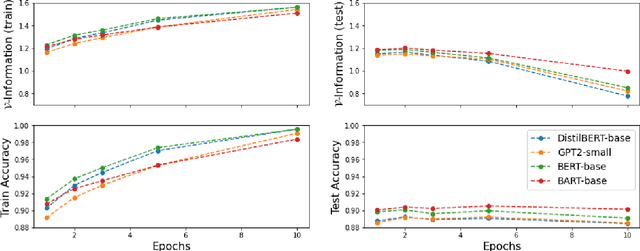
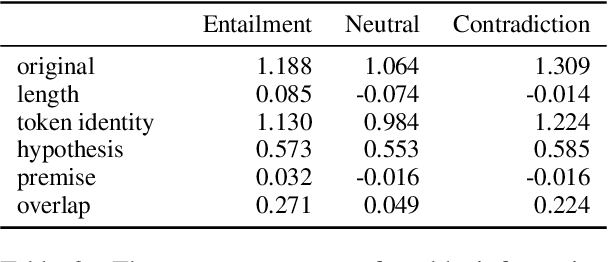
Estimating the difficulty of a dataset typically involves comparing state-of-the-art models to humans; the bigger the performance gap, the harder the dataset is said to be. Not only is this framework informal, but it also provides little understanding of how difficult each instance is, or what attributes make it difficult for a given model. To address these problems, we propose an information-theoretic perspective, framing dataset difficulty as the absence of $\textit{usable information}$. Measuring usable information is as easy as measuring performance, but has certain theoretical advantages. While the latter only allows us to compare different models w.r.t the same dataset, the former also allows us to compare different datasets w.r.t the same model. We then introduce $\textit{pointwise}$ $\mathcal{V}-$$\textit{information}$ (PVI) for measuring the difficulty of individual instances, where instances with higher PVI are easier for model $\mathcal{V}$. By manipulating the input before measuring usable information, we can understand $\textit{why}$ a dataset is easy or difficult for a given model, which we use to discover annotation artefacts in widely-used benchmarks.