 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Bottleneck Methods for Distributed Learning
Paper and Code
Oct 26, 2018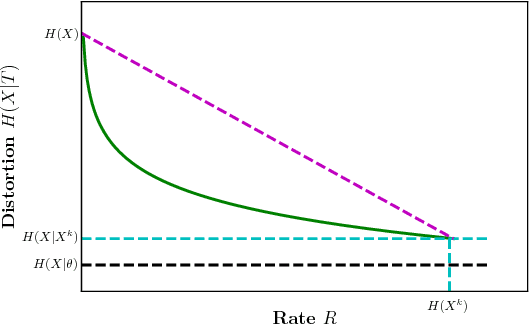
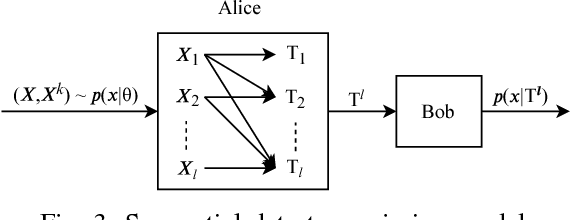
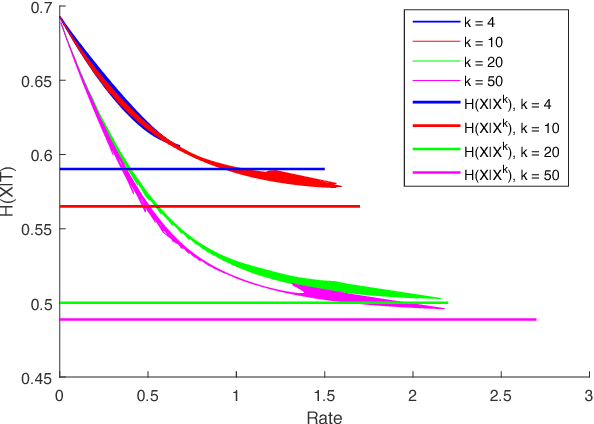
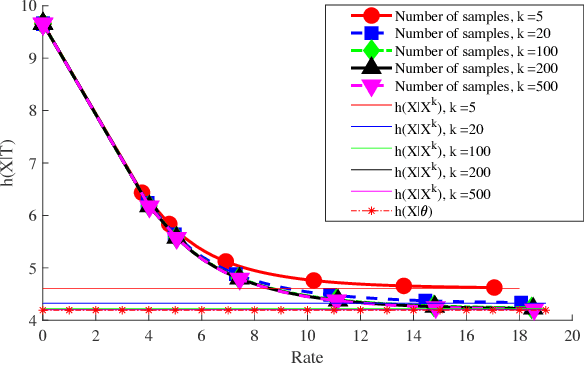
We study a distributed learning problem in which Alice sends a compressed distillation of a set of training data to Bob, who uses the distilled version to best solve an associated learning problem. We formalize this as a rate-distortion problem in which the training set is the source and Bob's cross-entropy loss is the distortion measure. We consider this problem for unsupervised learning for batch and sequential data. In the batch data, this problem is equivalent to the information bottleneck (IB), and we show that reduced-complexity versions of standard IB methods solve the associated rate-distortion problem. For the streaming data, we present a new algorithm, which may be of independent interest, that solves the rate-distortion problem for Gaussian sources. Furthermore, to improve the results of the iterative algorithm for sequential data we introduce a two-pass version of this algorithm. Finally, we show the dependency of the rate on the number of samples $k$ required for Gaussian sources to ensure cross-entropy loss that scales optimally with the growth of the training set.