 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInevitable Trade-off between Watermark Strength and Speculative Sampling Efficiency for Language Models
Paper and Code
Oct 27, 2024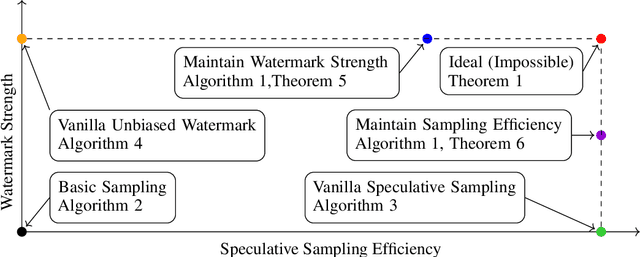
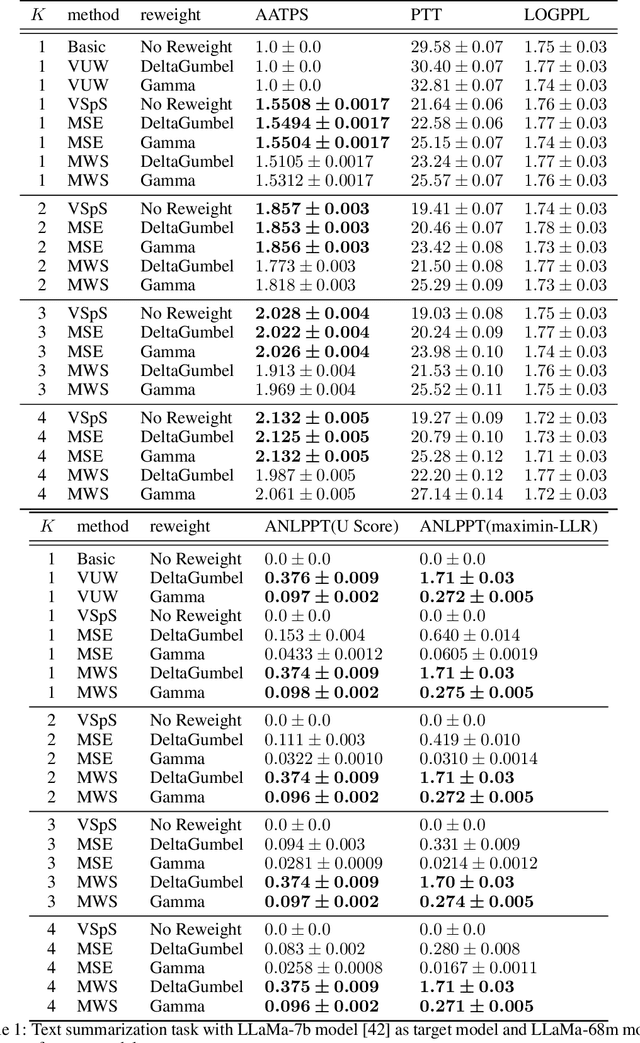
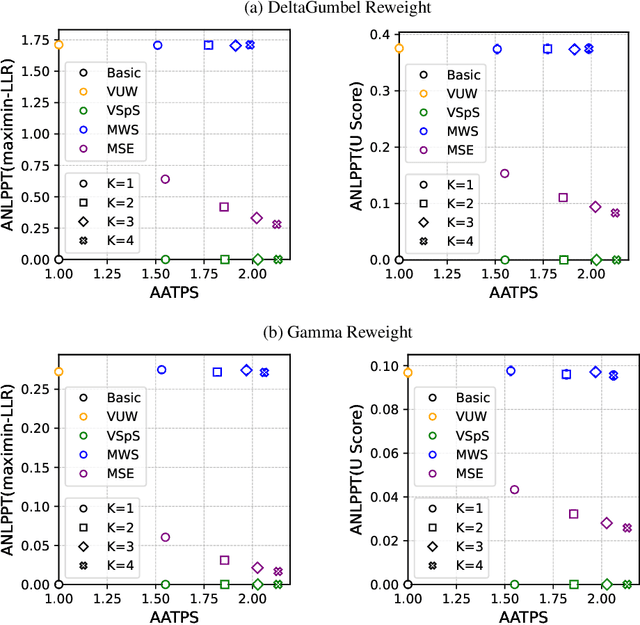
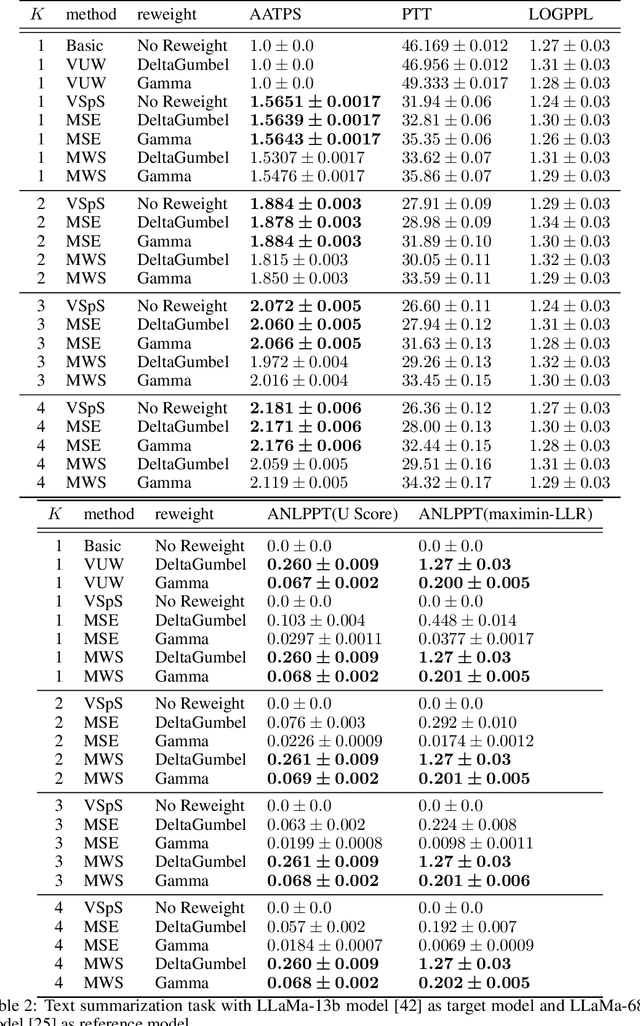
Large language models are probabilistic models, and the process of generating content is essentially sampling from the output distribution of the language model. Existing watermarking techniques inject watermarks into the generated content without altering the output quality. On the other hand, existing acceleration techniques, specifically speculative sampling, leverage a draft model to speed up the sampling process while preserving the output distribution. However, there is no known method to simultaneously accelerate the sampling process and inject watermarks into the generated content. In this paper, we investigate this direction and find that the integration of watermarking and acceleration is non-trivial. We prove a no-go theorem, which states that it is impossible to simultaneously maintain the highest watermark strength and the highest sampling efficiency. Furthermore, we propose two methods that maintain either the sampling efficiency or the watermark strength, but not both. Our work provides a rigorous theoretical foundation for understanding the inherent trade-off between watermark strength and sampling efficiency in accelerating the generation of watermarked tokens for large language models. We also conduct numerical experiments to validate our theoretical findings and demonstrate the effectiveness of the proposed methods.