 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Bias of Gradient Descent for Exponentially Weight Normalized Smooth Homogeneous Neural Nets
Paper and Code
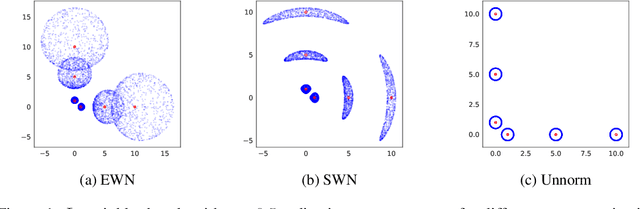
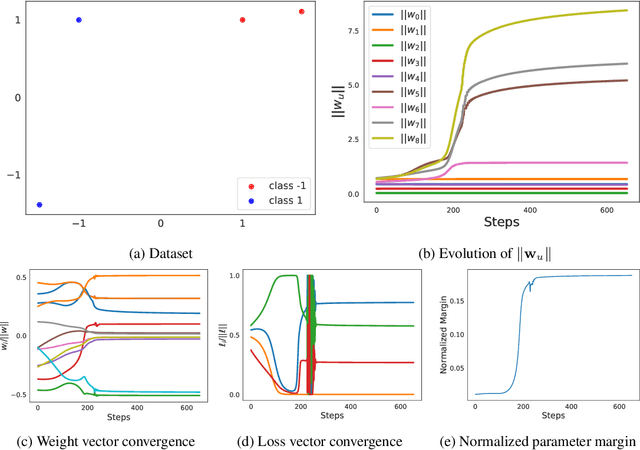
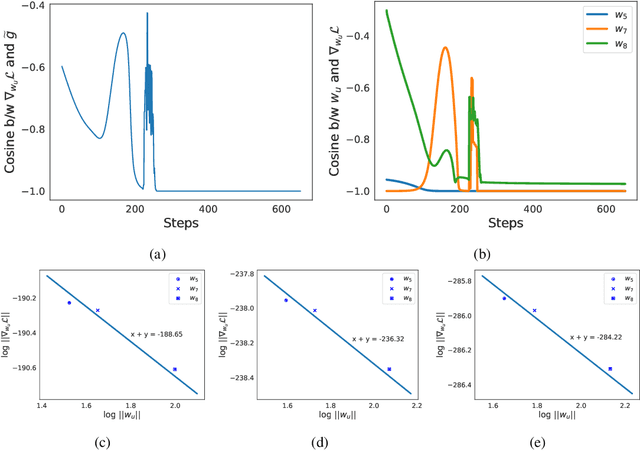
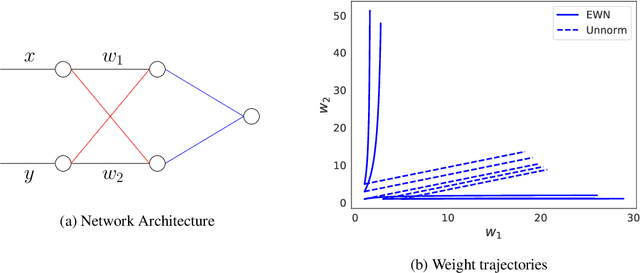
We analyze the inductive bias of gradient descent for weight normalized smooth homogeneous neural nets, when trained on exponential or cross-entropy loss. Our analysis focuses on exponential weight normalization (EWN), which encourages weight updates along the radial direction. This paper shows that the gradient flow path with EWN is equivalent to gradient flow on standard networks with an adaptive learning rate, and hence causes the weights to be updated in a way that prefers asymptotic relative sparsity. These results can be extended to hold for gradient descent via an appropriate adaptive learning rate. The asymptotic convergence rate of the loss in this setting is given by $\Theta(\frac{1}{t(\log t)^2})$, and is independent of the depth of the network. We contrast these results with the inductive bias of standard weight normalization (SWN) and unnormalized architectures, and demonstrate their implications on synthetic data sets.Experimental results on simple data sets and architectures support our claim on sparse EWN solutions, even with SGD. This demonstrates its potential applications in learning prunable neural networks.