 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndirect Local Attacks for Context-aware Semantic Segmentation Networks
Paper and Code


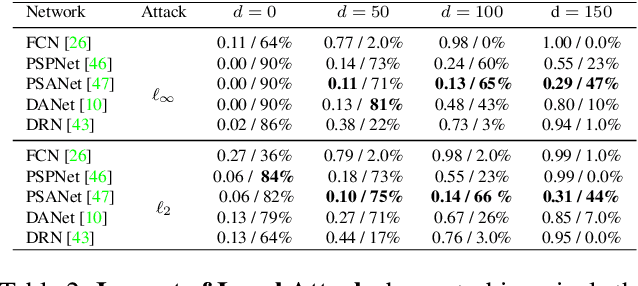

Recently, deep networks have achieved impressive semantic segmentation performance, in particular thanks to their use of larger contextual information. In this paper, we show that the resulting networks are sensitive not only to global attacks, where perturbations affect the entire input image, but also to indirect local attacks where perturbations are confined to a small image region that does not overlap with the area that we aim to fool. To this end, we introduce several indirect attack strategies, including adaptive local attacks, aiming to find the best image location to perturb, and universal local attacks. Furthermore, we propose attack detection techniques both for the global image level and to obtain a pixel-wise localization of the fooled regions. Our results are unsettling: Because they exploit a larger context, more accurate semantic segmentation networks are more sensitive to indirect local attacks.