 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Learning for Multi-organ Segmentation with Partially Labeled Datasets
Paper and Code
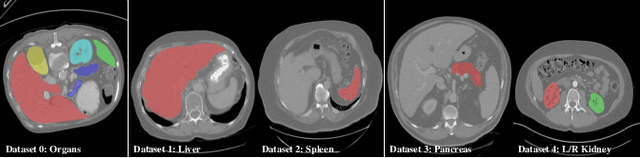
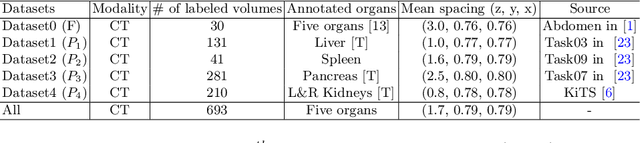
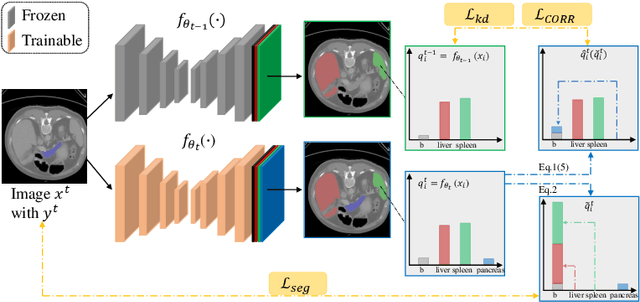
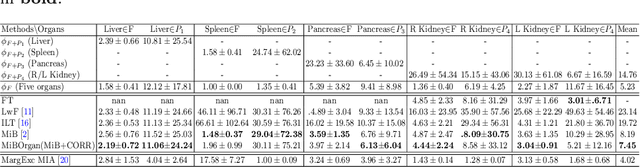
There exists a large number of datasets for organ segmentation, which are partially annotated, and sequentially constructed. A typical dataset is constructed at a certain time by curating medical images and annotating the organs of interest. In other words, new datasets with annotations of new organ categories are built over time. To unleash the potential behind these partially labeled, sequentially-constructed datasets, we propose to learn a multi-organ segmentation model through incremental learning (IL). In each IL stage, we lose access to the previous annotations, whose knowledge is assumingly captured by the current model, and gain the access to a new dataset with annotations of new organ categories, from which we learn to update the organ segmentation model to include the new organs. We give the first attempt to conjecture that the different distribution is the key reason for 'catastrophic forgetting' that commonly exists in IL methods, and verify that IL has the natural adaptability to medical image scenarios. Extensive experiments on five open-sourced datasets are conducted to prove the effectiveness of our method and the conjecture mentioned above.