 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Search for Architectures and Loss Functions in Multi-Objective Reinforcement Learning
Paper and Code
Jul 23, 2024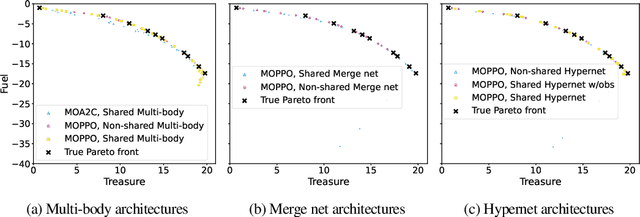

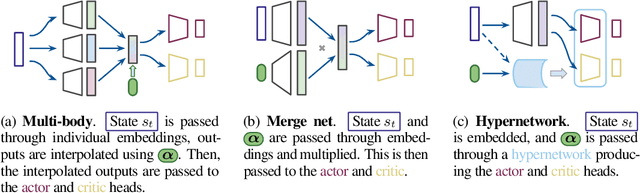

Multi-objective reinforcement learning (MORL) is essential for addressing the intricacies of real-world RL problems, which often require trade-offs between multiple utility functions. However, MORL is challenging due to unstable learning dynamics with deep learning-based function approximators. The research path most taken has been to explore different value-based loss functions for MORL to overcome this issue. Our work empirically explores model-free policy learning loss functions and the impact of different architectural choices. We introduce two different approaches: Multi-objective Proximal Policy Optimization (MOPPO), which extends PPO to MORL, and Multi-objective Advantage Actor Critic (MOA2C), which acts as a simple baseline in our ablations. Our proposed approach is straightforward to implement, requiring only small modifications at the level of function approximator. We conduct comprehensive evaluations on the MORL Deep Sea Treasure, Minecart, and Reacher environments and show that MOPPO effectively captures the Pareto front. Our extensive ablation studies and empirical analyses reveal the impact of different architectural choices, underscoring the robustness and versatility of MOPPO compared to popular MORL approaches like Pareto Conditioned Networks (PCN) and Envelope Q-learning in terms of MORL metrics, including hypervolume and expected utility.