 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning for Few-Shot Molecular Property Prediction
Paper and Code
Oct 13, 2023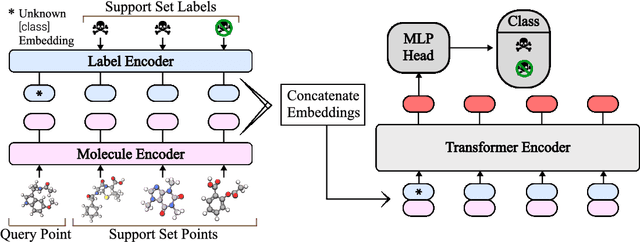
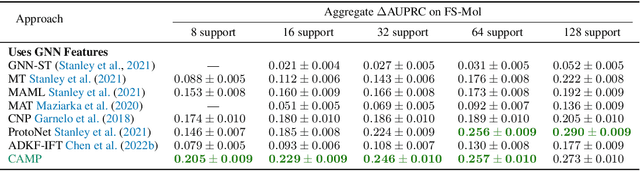
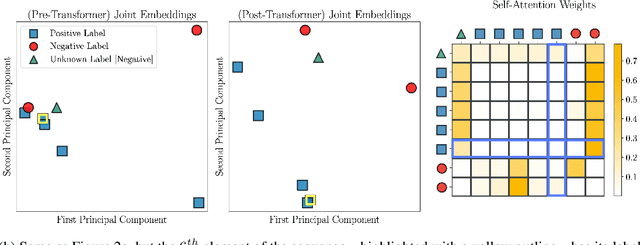
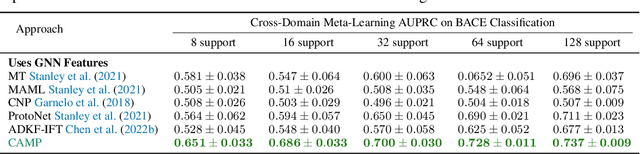
In-context learning has become an important approach for few-shot learning in Large Language Models because of its ability to rapidly adapt to new tasks without fine-tuning model parameters. However, it is restricted to applications in natural language and inapplicable to other domains. In this paper, we adapt the concepts underpinning in-context learning to develop a new algorithm for few-shot molecular property prediction. Our approach learns to predict molecular properties from a context of (molecule, property measurement) pairs and rapidly adapts to new properties without fine-tuning. On the FS-Mol and BACE molecular property prediction benchmarks, we find this method surpasses the performance of recent meta-learning algorithms at small support sizes and is competitive with the best methods at large support sizes.