 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the robustness and accuracy of biomedical language models through adversarial training
Paper and Code
Nov 16, 2021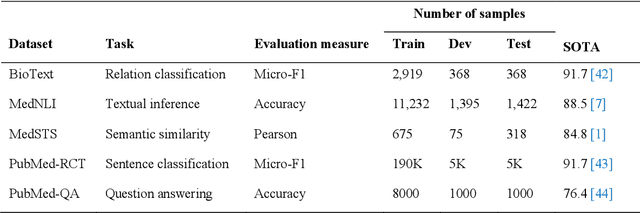
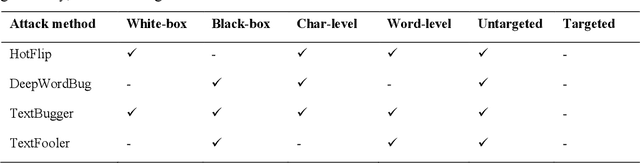
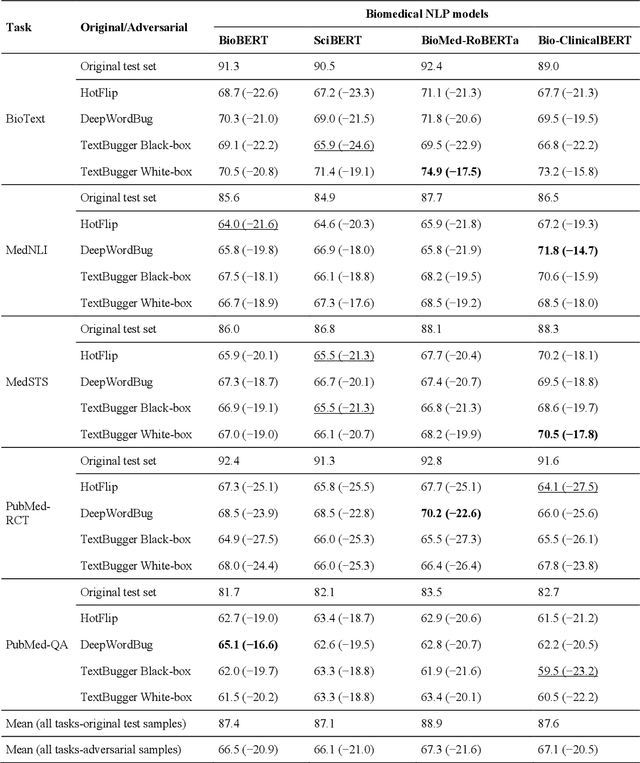
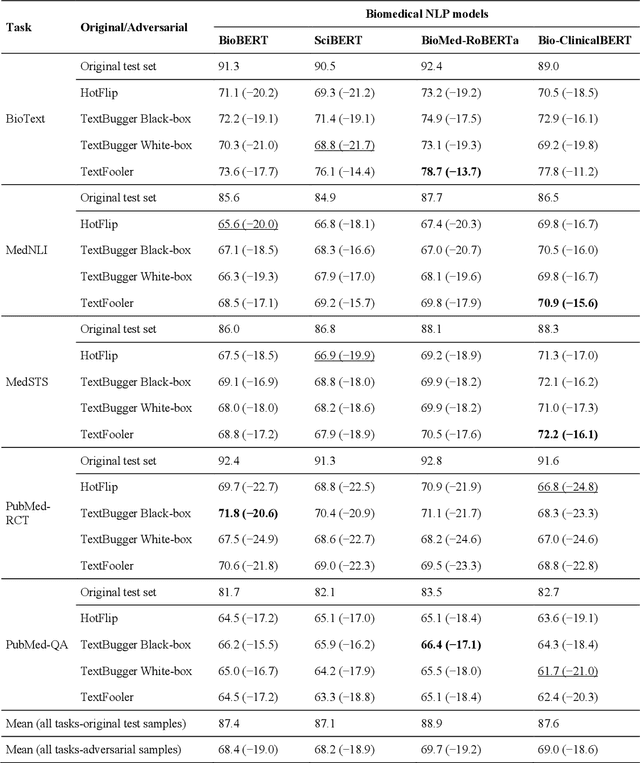
Deep transformer neural network models have improved the predictive accuracy of intelligent text processing systems in the biomedical domain. They have obtained state-of-the-art performance scores on a wide variety of biomedical and clinical Natural Language Processing (NLP) benchmarks. However, the robustness and reliability of these models has been less explored so far. Neural NLP models can be easily fooled by adversarial samples, i.e. minor changes to input that preserve the meaning and understandability of the text but force the NLP system to make erroneous decisions. This raises serious concerns about the security and trust-worthiness of biomedical NLP systems, especially when they are intended to be deployed in real-world use cases. We investigated the robustness of several transformer neural language models, i.e. BioBERT, SciBERT, BioMed-RoBERTa, and Bio-ClinicalBERT, on a wide range of biomedical and clinical text processing tasks. We implemented various adversarial attack methods to test the NLP systems in different attack scenarios. Experimental results showed that the biomedical NLP models are sensitive to adversarial samples; their performance dropped in average by 21 and 18.9 absolute percent on character-level and word-level adversarial noise, respectively. Conducting extensive adversarial training experiments, we fine-tuned the NLP models on a mixture of clean samples and adversarial inputs. Results showed that adversarial training is an effective defense mechanism against adversarial noise; the models robustness improved in average by 11.3 absolute percent. In addition, the models performance on clean data increased in average by 2.4 absolute present, demonstrating that adversarial training can boost generalization abilities of biomedical NLP systems.