 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the affordability of robustness training for DNNs
Paper and Code
Feb 11, 2020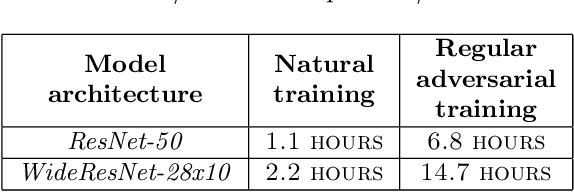
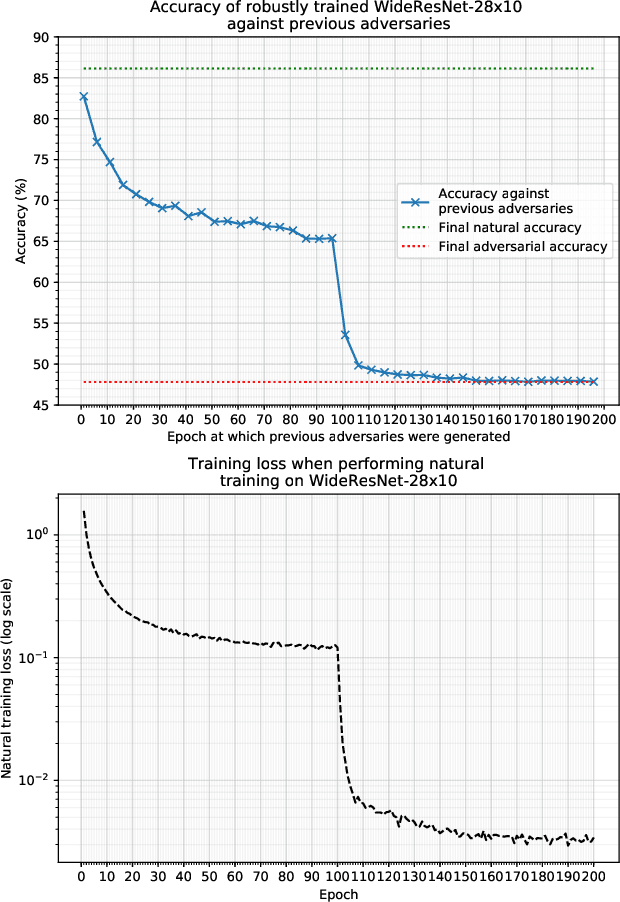
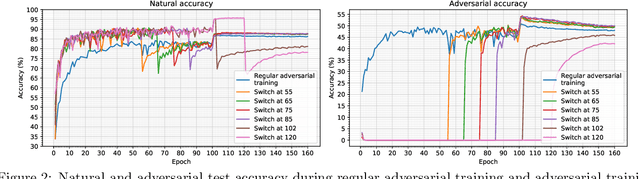
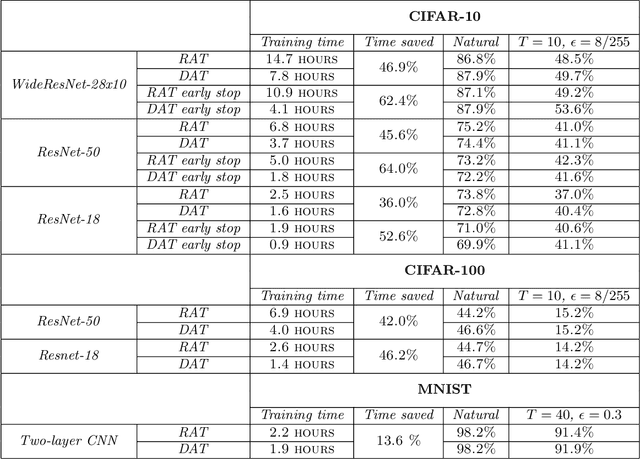
Projected Gradient Descent (PGD) based adversarial training has become one of the most prominent methods for building robust deep neural network models. However, the computational complexity associated with this approach, due to the maximization of the loss function when finding adversaries, is a longstanding problem and may be prohibitive when using larger and more complex models. In this paper, we propose a modification of the PGD method for adversarial training and demonstrate that models can be trained much more efficiently without any loss in accuracy on natural and adversarial samples. We argue that the initial phase of adversarial training is redundant and can be replaced with natural training thereby increasing the computational efficiency significantly. We support our argument with insights on the nature of the adversaries and their relative strength during the training process. We show that our proposed method can reduce the training time to up to 38\% of the original training time with comparable model accuracy and generalization on various strengths of adversarial attacks.