 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Spectral Clustering Using Spectrum-Preserving Node Reduction
Paper and Code


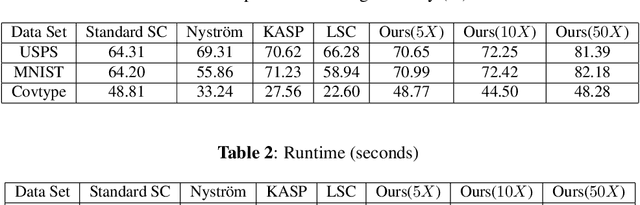
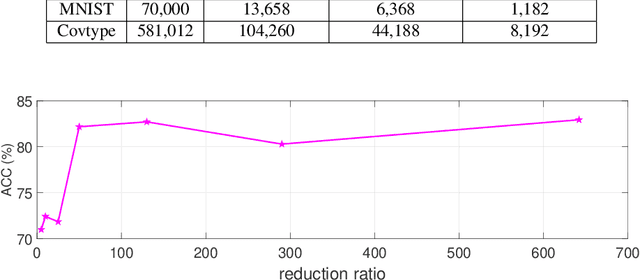
Spectral clustering is one of the most popular clustering methods. However, the high computational cost due to the involved eigen-decomposition procedure can immediately hinder its applications in large-scale tasks. In this paper we use spectrum-preserving node reduction to accelerate eigen-decomposition and generate concise representations of data sets. Specifically, we create a small number of pseudonodes based on spectral similarity. Then, standard spectral clustering algorithm is performed on the smaller node set. Finally, each data point in the original data set is assigned to the cluster as its representative pseudo-node. The proposed framework run in nearly-linear time. Meanwhile, the clustering accuracy can be significantly improved by mining concise representations. The experimental results show dramatically improved clustering performance when compared with state-of-the-art methods.