 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sentence Similarity Estimation for Unsupervised Extractive Summarization
Paper and Code
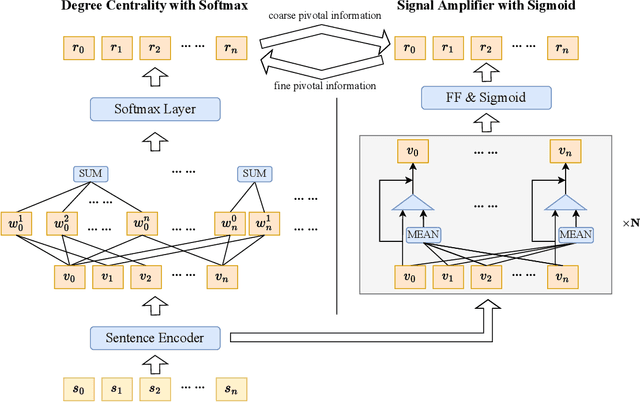
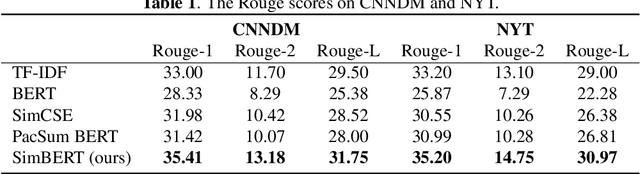
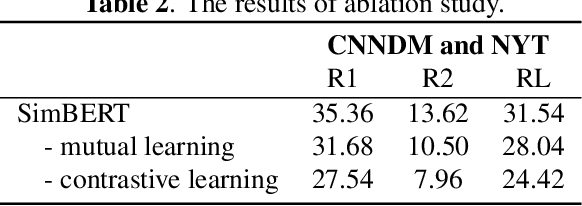
Unsupervised extractive summarization aims to extract salient sentences from a document as the summary without labeled data. Recent literatures mostly research how to leverage sentence similarity to rank sentences in the order of salience. However, sentence similarity estimation using pre-trained language models mostly takes little account of document-level information and has a weak correlation with sentence salience ranking. In this paper, we proposed two novel strategies to improve sentence similarity estimation for unsupervised extractive summarization. We use contrastive learning to optimize a document-level objective that sentences from the same document are more similar than those from different documents. Moreover, we use mutual learning to enhance the relationship between sentence similarity estimation and sentence salience ranking, where an extra signal amplifier is used to refine the pivotal information. Experimental results demonstrate the effectiveness of our strategies.