Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Semi-Supervised Learning for Remaining Useful Lifetime Estimation Through Self-Supervision
Paper and Code
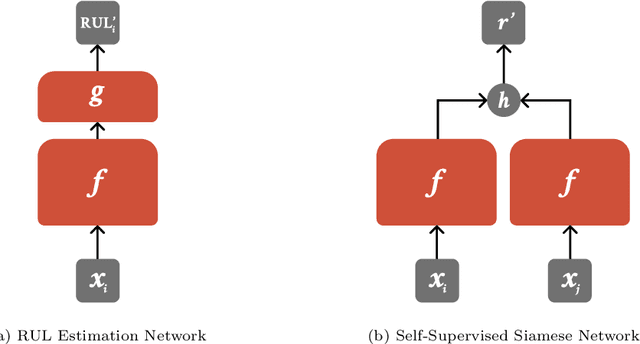

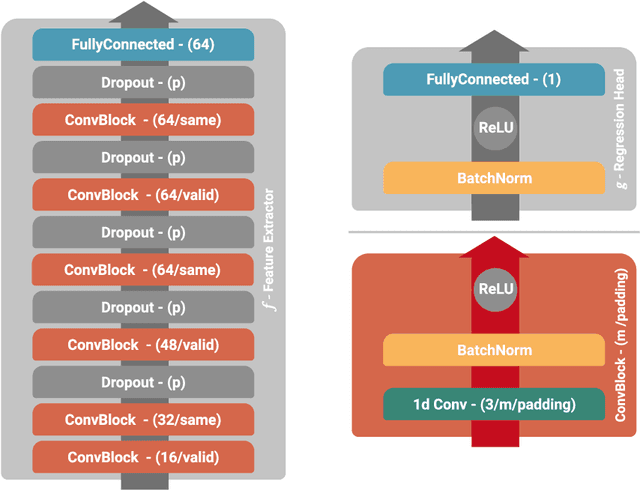

RUL estimation suffers from a server data imbalance where data from machines near their end of life is rare. Additionally, the data produced by a machine can only be labeled after the machine failed. Semi-Supervised Learning (SSL) can incorporate the unlabeled data produced by machines that did not yet fail. Previous work on SSL evaluated their approaches under unrealistic conditions where the data near failure was still available. Even so, only moderate improvements were made. This paper proposes a novel SSL approach based on self-supervised pre-training. The method can outperform two competing approaches from the literature and a supervised baseline under realistic conditions on the NASA C-MAPSS dataset.
* Updated manuscript
View paper on