Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reverberant Speech Training Using Diffuse Acoustic Simulation
Paper and Code
Jul 09, 2019


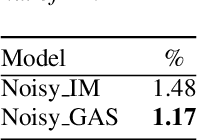
We present an efficient and realistic geometric sound simulation approach for generating and augmenting training data in speech-related machine learning tasks. Our physically based acoustic simulation method is capable of modeling occlusion, specular and diffuse reflections of sound in complicated acoustic environments, whereas the classical image method can only model specular reflections in simple room settings. We show that by using our synthetic training data, the same models gain significant performance improvement on real test sets in both speech recognition and keyword spotting tasks, without fine tuning using any real data.
View paper on