 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Proper Noun Recognition in End-to-End ASR By Customization of the MWER Loss Criterion
Paper and Code
May 19, 2020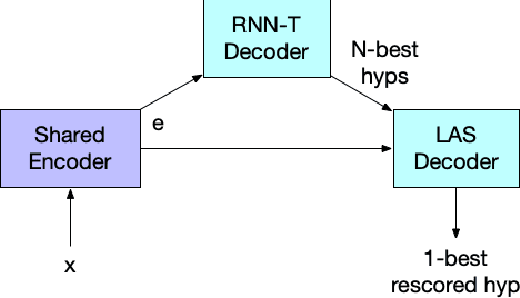
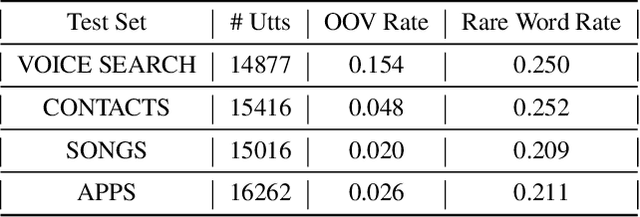
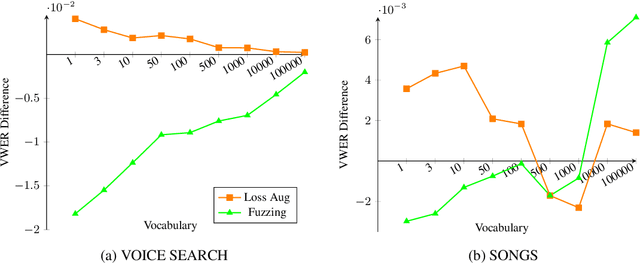

Proper nouns present a challenge for end-to-end (E2E) automatic speech recognition (ASR) systems in that a particular name may appear only rarely during training, and may have a pronunciation similar to that of a more common word. Unlike conventional ASR models, E2E systems lack an explicit pronounciation model that can be specifically trained with proper noun pronounciations and a language model that can be trained on a large text-only corpus. Past work has addressed this issue by incorporating additional training data or additional models. In this paper, we instead build on recent advances in minimum word error rate (MWER) training to develop two new loss criteria that specifically emphasize proper noun recognition. Unlike past work on this problem, this method requires no new data during training or external models during inference. We see improvements ranging from 2% to 7% relative on several relevant benchmarks.