 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving part-of-speech tagging via multi-task learning and character-level word representations
Paper and Code
Jul 02, 2018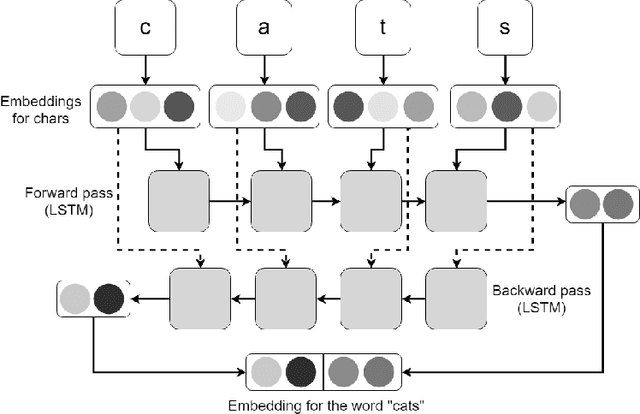

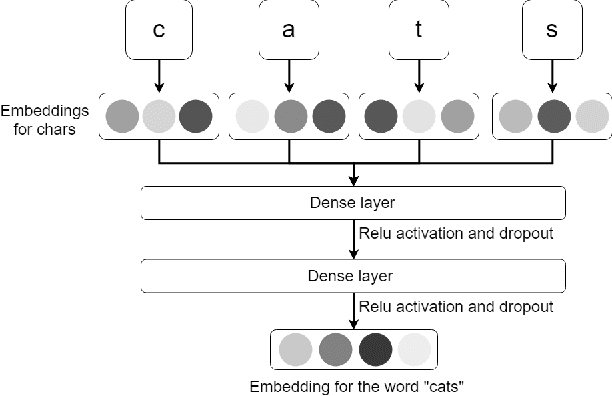

In this paper, we explore the ways to improve POS-tagging using various types of auxiliary losses and different word representations. As a baseline, we utilized a BiLSTM tagger, which is able to achieve state-of-the-art results on the sequence labelling tasks. We developed a new method for character-level word representation using feedforward neural network. Such representation gave us better results in terms of speed and performance of the model. We also applied a novel technique of pretraining such word representations with existing word vectors. Finally, we designed a new variant of auxiliary loss for sequence labelling tasks: an additional prediction of the neighbour labels. Such loss forces a model to learn the dependencies in-side a sequence of labels and accelerates the process of training. We test these methods on English and Russian languages.