 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Few-Shot Cross-Domain Named Entity Recognition by Instruction Tuning a Word-Embedding based Retrieval Augmented Large Language Model
Paper and Code
Nov 01, 2024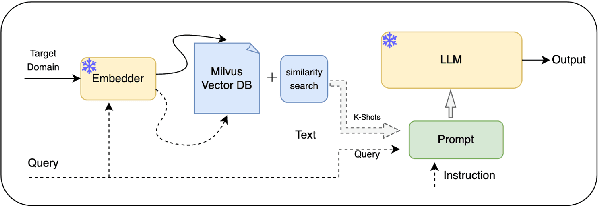
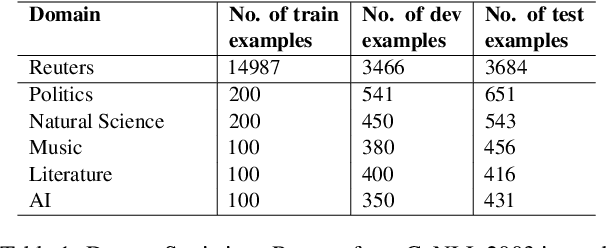
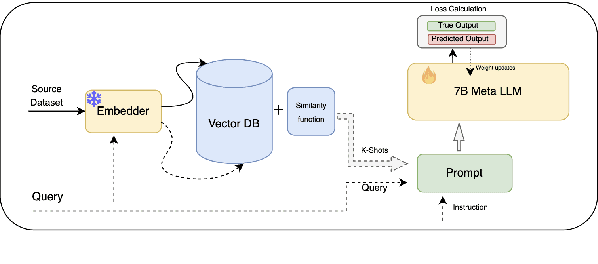
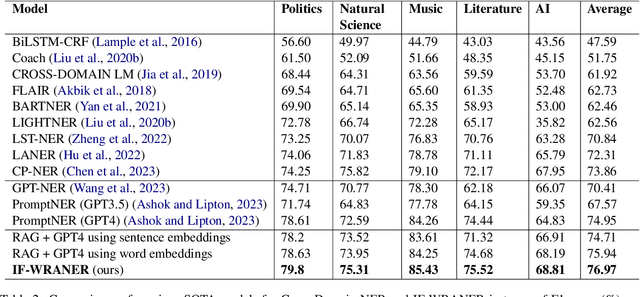
Few-Shot Cross-Domain NER is the process of leveraging knowledge from data-rich source domains to perform entity recognition on data scarce target domains. Most previous state-of-the-art (SOTA) approaches use pre-trained language models (PLMs) for cross-domain NER. However, these models are often domain specific. To successfully use these models for new target domains, we need to modify either the model architecture or perform model finetuning using data from the new domains. Both of these result in the creation of entirely new NER models for each target domain which is infeasible for practical scenarios. Recently,several works have attempted to use LLMs to solve Few-Shot Cross-Domain NER. However, most of these are either too expensive for practical purposes or struggle to follow LLM prompt instructions. In this paper, we propose IF-WRANER (Instruction Finetuned Word-embedding based Retrieval Augmented large language model for Named Entity Recognition), a retrieval augmented LLM, finetuned for the NER task. By virtue of the regularization techniques used during LLM finetuning and the adoption of word-level embedding over sentence-level embedding during the retrieval of in-prompt examples, IF-WRANER is able to outperform previous SOTA Few-Shot Cross-Domain NER approaches. We have demonstrated the effectiveness of our model by benchmarking its performance on the open source CrossNER dataset, on which it shows more than 2% F1 score improvement over the previous SOTA model. We have deployed the model for multiple customer care domains of an enterprise. Accurate entity prediction through IF-WRANER helps direct customers to automated workflows for the domains, thereby reducing escalations to human agents by almost 15% and leading to millions of dollars in yearly savings for the company.