 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Discourse Relation Projection to Build Discourse Annotated Corpora
Paper and Code
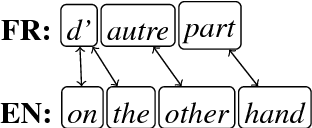

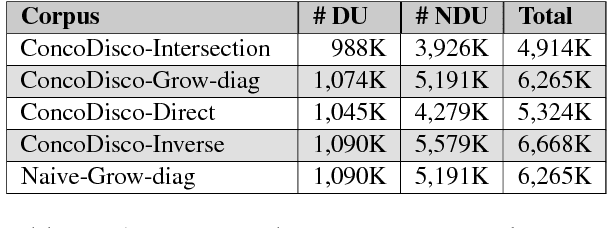
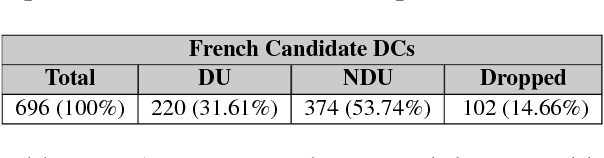
The naive approach to annotation projection is not effective to project discourse annotations from one language to another because implicit discourse relations are often changed to explicit ones and vice-versa in the translation. In this paper, we propose a novel approach based on the intersection between statistical word-alignment models to identify unsupported discourse annotations. This approach identified 65% of the unsupported annotations in the English-French parallel sentences from Europarl. By filtering out these unsupported annotations, we induced the first PDTB-style discourse annotated corpus for French from Europarl. We then used this corpus to train a classifier to identify the discourse-usage of French discourse connectives and show a 15% improvement of F1-score compared to the classifier trained on the non-filtered annotations.