 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Deep Reinforcement Learning by Reducing the Chain Effect of Value and Policy Churn
Paper and Code
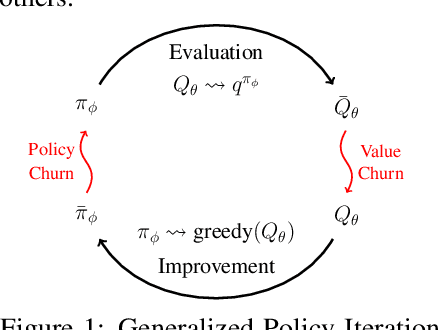

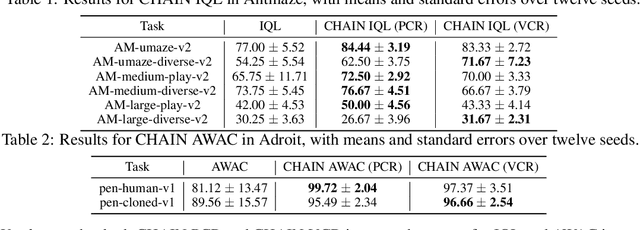

Deep neural networks provide Reinforcement Learning (RL) powerful function approximators to address large-scale decision-making problems. However, these approximators introduce challenges due to the non-stationary nature of RL training. One source of the challenges in RL is that output predictions can churn, leading to uncontrolled changes after each batch update for states not included in the batch. Although such a churn phenomenon exists in each step of network training, how churn occurs and impacts RL remains under-explored. In this work, we start by characterizing churn in a view of Generalized Policy Iteration with function approximation, and we discover a chain effect of churn that leads to a cycle where the churns in value estimation and policy improvement compound and bias the learning dynamics throughout the iteration. Further, we concretize the study and focus on the learning issues caused by the chain effect in different settings, including greedy action deviation in value-based methods, trust region violation in proximal policy optimization, and dual bias of policy value in actor-critic methods. We then propose a method to reduce the chain effect across different settings, called Churn Approximated ReductIoN (CHAIN), which can be easily plugged into most existing DRL algorithms. Our experiments demonstrate the effectiveness of our method in both reducing churn and improving learning performance across online and offline, value-based and policy-based RL settings, as well as a scaling setting.