 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Coordination in Multi-Agent Deep Reinforcement Learning through Memory-driven Communication
Paper and Code



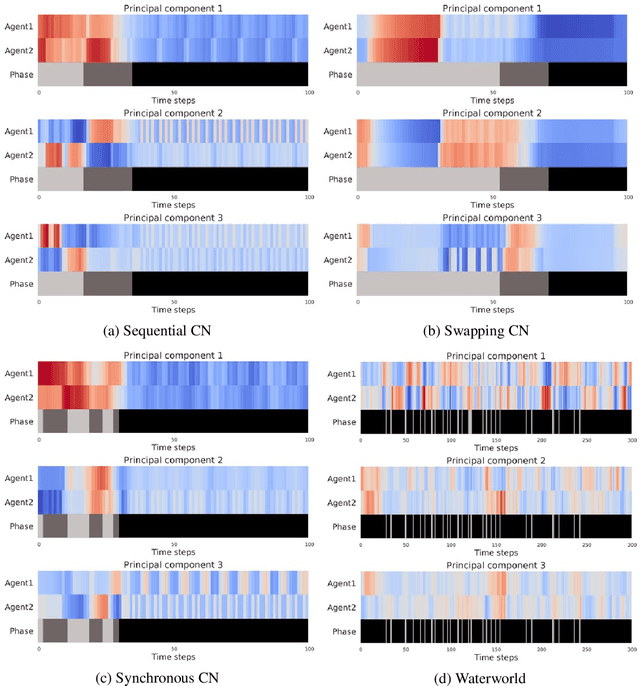
Deep reinforcement learning algorithms have recently been used to train multiple interacting agents in a centralised manner whilst keeping their execution decentralised. When the agents can only acquire partial observations and are faced with a task requiring coordination and synchronisation skills, inter-agent communication plays an essential role. In this work, we propose a framework for multi-agent training using deep deterministic policy gradients that enables the concurrent, end-to-end learning of an explicit communication protocol through a memory device. During training, the agents learn to perform read and write operations enabling them to infer a shared representation of the world. We empirically demonstrate that concurrent learning of the communication device and individual policies can improve inter-agent coordination and performance, and illustrate how different communication patterns can emerge for different tasks.