 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Classifier Training Efficiency for Automatic Cyberbullying Detection with Feature Density
Paper and Code
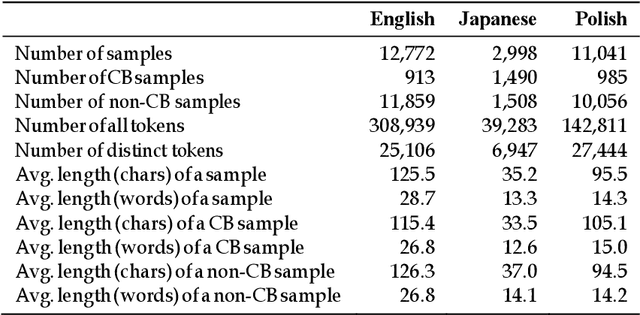
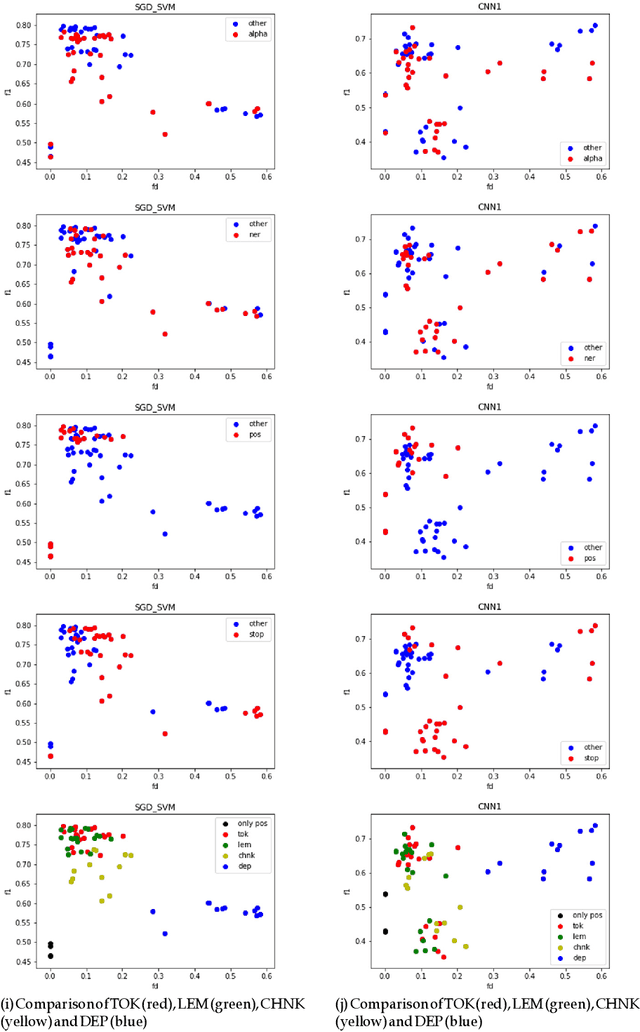
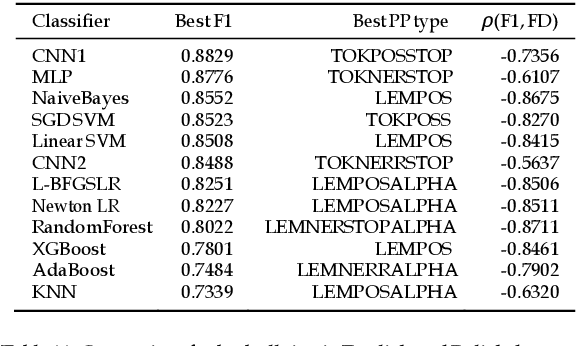
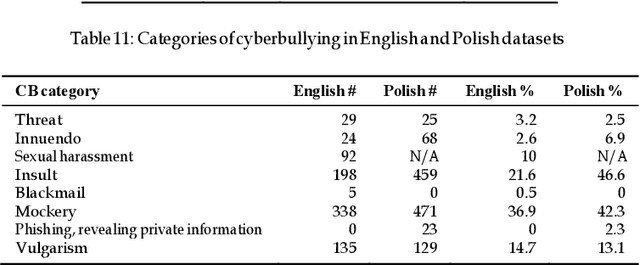
We study the effectiveness of Feature Density (FD) using different linguistically-backed feature preprocessing methods in order to estimate dataset complexity, which in turn is used to comparatively estimate the potential performance of machine learning (ML) classifiers prior to any training. We hypothesise that estimating dataset complexity allows for the reduction of the number of required experiments iterations. This way we can optimize the resource-intensive training of ML models which is becoming a serious issue due to the increases in available dataset sizes and the ever rising popularity of models based on Deep Neural Networks (DNN). The problem of constantly increasing needs for more powerful computational resources is also affecting the environment due to alarmingly-growing amount of CO2 emissions caused by training of large-scale ML models. The research was conducted on multiple datasets, including popular datasets, such as Yelp business review dataset used for training typical sentiment analysis models, as well as more recent datasets trying to tackle the problem of cyberbullying, which, being a serious social problem, is also a much more sophisticated problem form the point of view of linguistic representation. We use cyberbullying datasets collected for multiple languages, namely English, Japanese and Polish. The difference in linguistic complexity of datasets allows us to additionally discuss the efficacy of linguistically-backed word preprocessing.