 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Bi-directional Generation between Different Modalities with Variational Autoencoders
Paper and Code
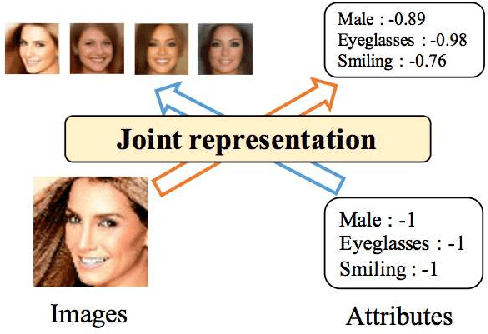
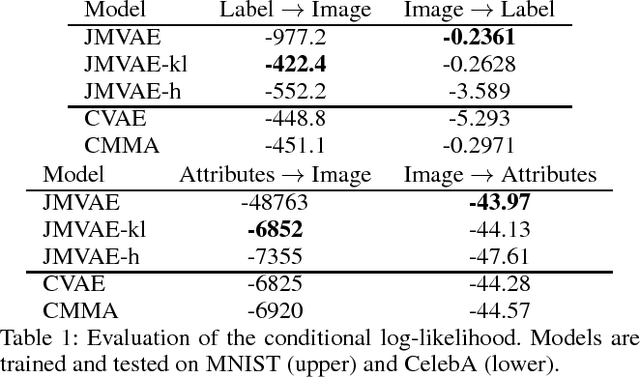
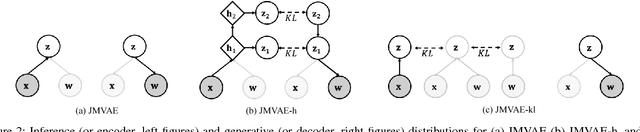

We investigate deep generative models that can exchange multiple modalities bi-directionally, e.g., generating images from corresponding texts and vice versa. A major approach to achieve this objective is to train a model that integrates all the information of different modalities into a joint representation and then to generate one modality from the corresponding other modality via this joint representation. We simply applied this approach to variational autoencoders (VAEs), which we call a joint multimodal variational autoencoder (JMVAE). However, we found that when this model attempts to generate a large dimensional modality missing at the input, the joint representation collapses and this modality cannot be generated successfully. Furthermore, we confirmed that this difficulty cannot be resolved even using a known solution. Therefore, in this study, we propose two models to prevent this difficulty: JMVAE-kl and JMVAE-h. Results of our experiments demonstrate that these methods can prevent the difficulty above and that they generate modalities bi-directionally with equal or higher likelihood than conventional VAE methods, which generate in only one direction. Moreover, we confirm that these methods can obtain the joint representation appropriately, so that they can generate various variations of modality by moving over the joint representation or changing the value of another modality.