Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Super-Resolution Convolution Neural Network for Large Images
Paper and Code
Jul 26, 2019
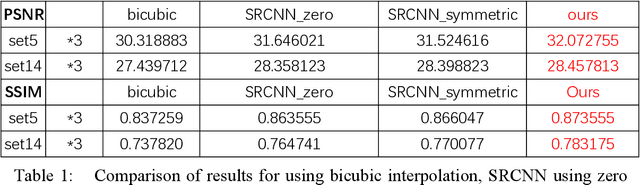
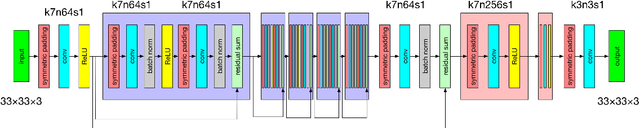

Single image super-resolution (SISR) is a very popular topic nowadays, which has both research value and practical value. In daily life, we crop a large image into sub-images to do super-resolution and then merge them together. Although convolution neural network performs very well in the research field, if we use it to do super-resolution, we can easily observe cutting lines from merged pictures. To address these problems, in this paper, we propose a refined architecture of SRCNN with 'Symmetric padding', 'Random learning' and 'Residual learning'. Moreover, we have done a lot of experiments to prove our model performs best among a lot of the state-of-art methods.
View paper on