 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit recurrent networks: A novel approach to stationary input processing with recurrent neural networks in deep learning
Paper and Code
Oct 20, 2020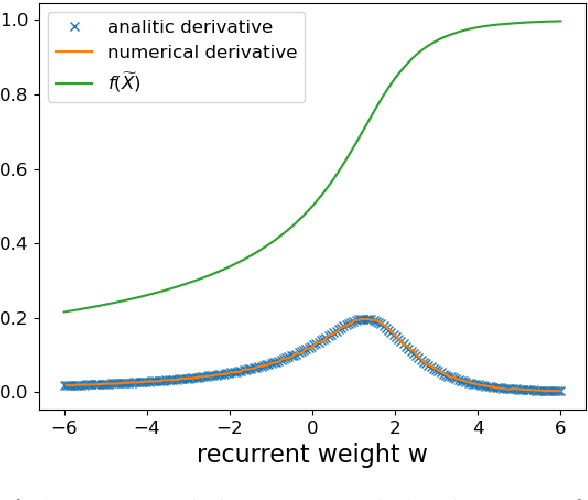
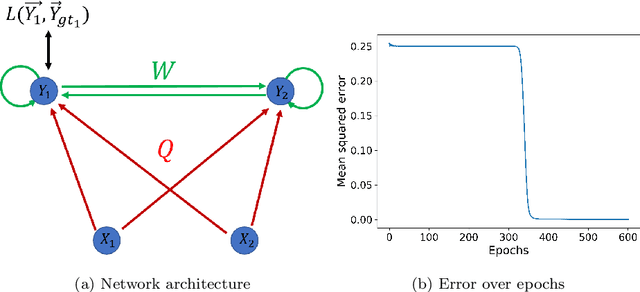
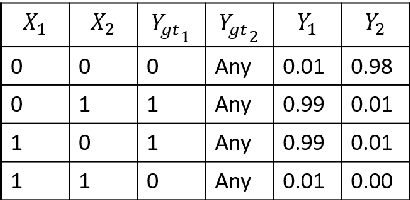
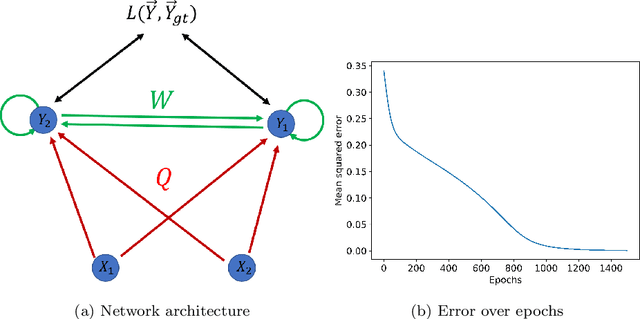
The brain cortex, which processes visual, auditory and sensory data in the brain, is known to have many recurrent connections within its layers and from higher to lower layers. But, in the case of machine learning with neural networks, it is generally assumed that strict feed-forward architectures are suitable for static input data, such as images, whereas recurrent networks are required mainly for the processing of sequential input, such as language. However, it is not clear whether also processing of static input data benefits from recurrent connectivity. In this work, we introduce and test a novel implementation of recurrent neural networks with lateral and feed-back connections into deep learning. This departure from the strict feed-forward structure prevents the use of the standard error backpropagation algorithm for training the networks. Therefore we provide an algorithm which implements the backpropagation algorithm on a implicit implementation of recurrent networks, which is different from state-of-the-art implementations of recurrent neural networks. Our method, in contrast to current recurrent neural networks, eliminates the use of long chains of derivatives due to many iterative update steps, which makes learning computationally less costly. It turns out that the presence of recurrent intra-layer connections within a one-layer implicit recurrent network enhances the performance of neural networks considerably: A single-layer implicit recurrent network is able to solve the XOR problem, while a feed-forward network with monotonically increasing activation function fails at this task. Finally, we demonstrate that a two-layer implicit recurrent architecture leads to a better performance in a regression task of physical parameters from the measured trajectory of a damped pendulum.