 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of regularization on Spectral Clustering
Paper and Code
Jul 21, 2014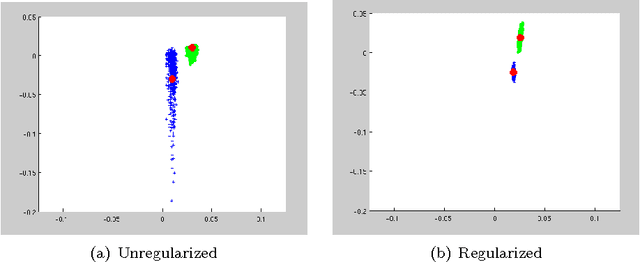
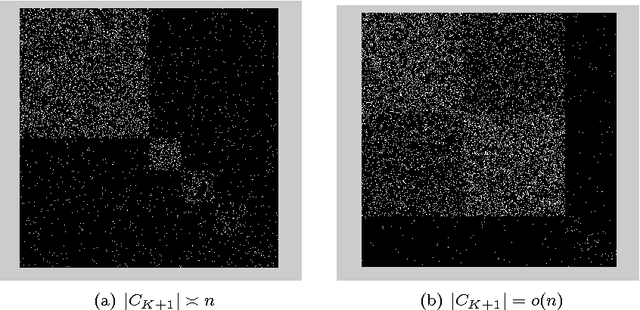
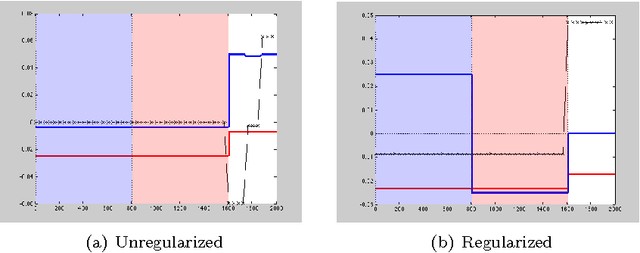
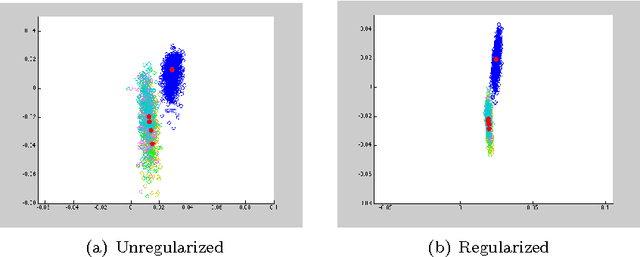
The performance of spectral clustering can be considerably improved via regularization, as demonstrated empirically in Amini et. al (2012). Here, we provide an attempt at quantifying this improvement through theoretical analysis. Under the stochastic block model (SBM), and its extensions, previous results on spectral clustering relied on the minimum degree of the graph being sufficiently large for its good performance. By examining the scenario where the regularization parameter $\tau$ is large we show that the minimum degree assumption can potentially be removed. As a special case, for an SBM with two blocks, the results require the maximum degree to be large (grow faster than $\log n$) as opposed to the minimum degree. More importantly, we show the usefulness of regularization in situations where not all nodes belong to well-defined clusters. Our results rely on a `bias-variance'-like trade-off that arises from understanding the concentration of the sample Laplacian and the eigen gap as a function of the regularization parameter. As a byproduct of our bounds, we propose a data-driven technique \textit{DKest} (standing for estimated Davis-Kahan bounds) for choosing the regularization parameter. This technique is shown to work well through simulations and on a real data set.