 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMHO Fine-Tuning Improves Claim Detection
Paper and Code
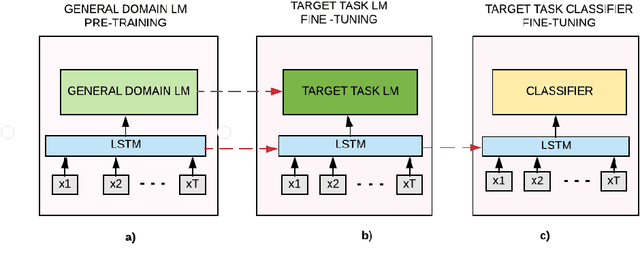
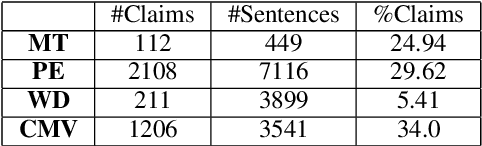
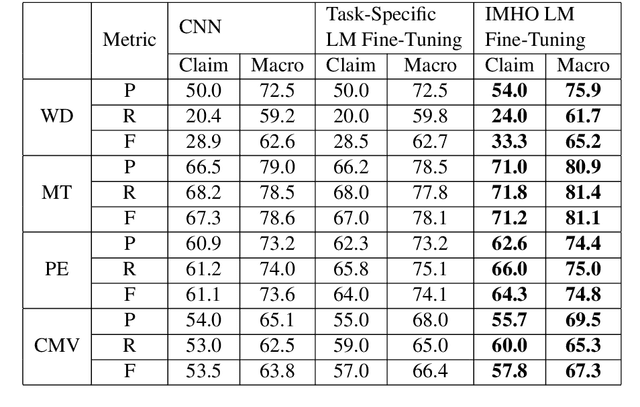
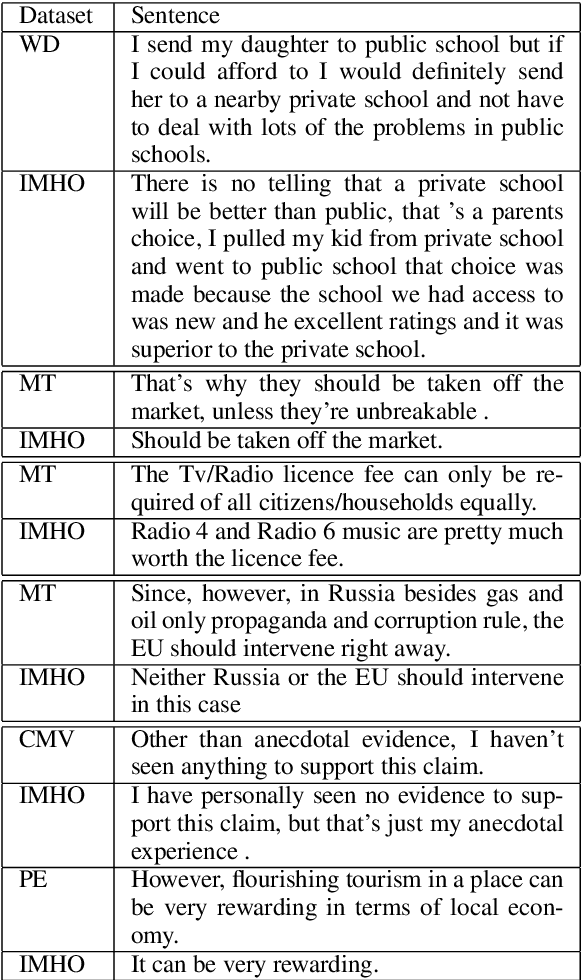
Claims are the central component of an argument. Detecting claims across different domains or data sets can often be challenging due to their varying conceptualization. We propose to alleviate this problem by fine tuning a language model using a Reddit corpus of 5.5 million opinionated claims. These claims are self-labeled by their authors using the internet acronyms IMO/IMHO (in my (humble) opinion). Empirical results show that using this approach improves the state of art performance across four benchmark argumentation data sets by an average of 4 absolute F1 points in claim detection. As these data sets include diverse domains such as social media and student essays this improvement demonstrates the robustness of fine-tuning on this novel corpus.