 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImbalanced Deep Learning by Minority Class Incremental Rectification
Paper and Code

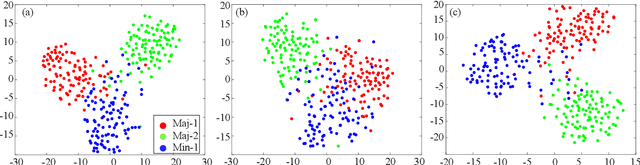


Model learning from class imbalanced training data is a long-standing and significant challenge for machine learning. In particular, existing deep learning methods consider mostly either class balanced data or moderately imbalanced data in model training, and ignore the challenge of learning from significantly imbalanced training data. To address this problem, we formulate a class imbalanced deep learning model based on batch-wise incremental minority (sparsely sampled) class rectification by hard sample mining in majority (frequently sampled) classes during model training. This model is designed to minimise the dominant effect of majority classes by discovering sparsely sampled boundaries of minority classes in an iterative batch-wise learning process. To that end, we introduce a Class Rectification Loss (CRL) function that can be deployed readily in deep network architectures. Extensive experimental evaluations are conducted on three imbalanced person attribute benchmark datasets (CelebA, X-Domain, DeepFashion) and one balanced object category benchmark dataset (CIFAR-100). These experimental results demonstrate the performance advantages and model scalability of the proposed batch-wise incremental minority class rectification model over the existing state-of-the-art models for addressing the problem of imbalanced data learning.