Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Weaknesses in Machine Translation Metrics Through Minimum Bayes Risk Decoding: A Case Study for COMET
Paper and Code

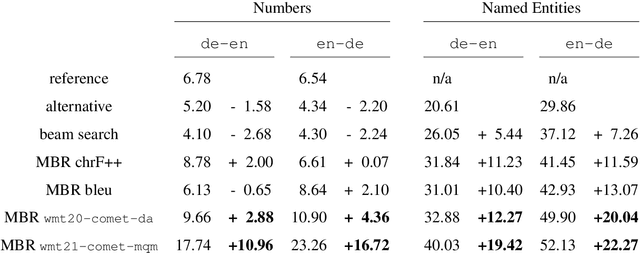
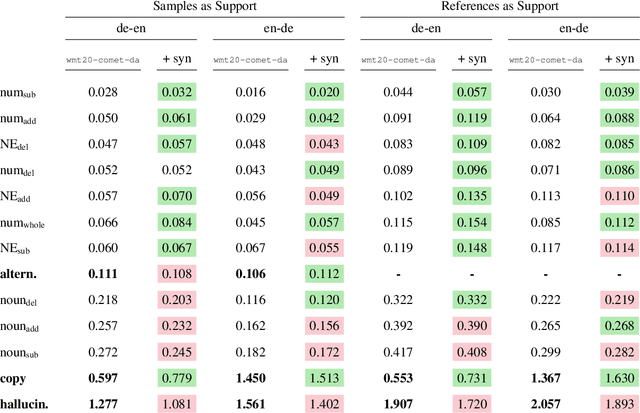

Neural metrics have achieved impressive correlation with human judgements in the evaluation of machine translation systems, but before we can safely optimise towards such metrics, we should be aware of (and ideally eliminate) biases towards bad translations that receive high scores. Our experiments show that sample-based Minimum Bayes Risk decoding can be used to explore and quantify such weaknesses. When applying this strategy to COMET for en-de and de-en, we find that COMET models are not sensitive enough to discrepancies in numbers and named entities. We further show that these biases cannot be fully removed by simply training on additional synthetic data.
View paper on